GPU와 Xeon Phi를 활용한 대규모 유전체 상관계수 계산 가속화
초록
본 논문은 SNP 간의 Custom Correlation Coefficient(CCC)를 고성능 GPU와 Intel Xeon Phi 가속기에서 효율적으로 계산하기 위한 알고리즘과 구현을 제시한다. 2‑way와 3‑way CCC를 행렬‑행렬 곱(GEMM) 형태로 변형하고, 비트‑레벨 연산과 하드웨어 인구수(popcount) 명령을 활용해 연산량을 크게 줄인다. 또한 대규모 클러스터에서의 데이터 분할·중복 제거 전략을 통해 거의 이상적인 확장성을 달성했으며, ORNL Titan 시스템에서 초당 9 × 10¹⁵개의 원소 비교, 향후 Summit에서는 9 × 10¹⁶개 수준을 예측한다.
상세 분석
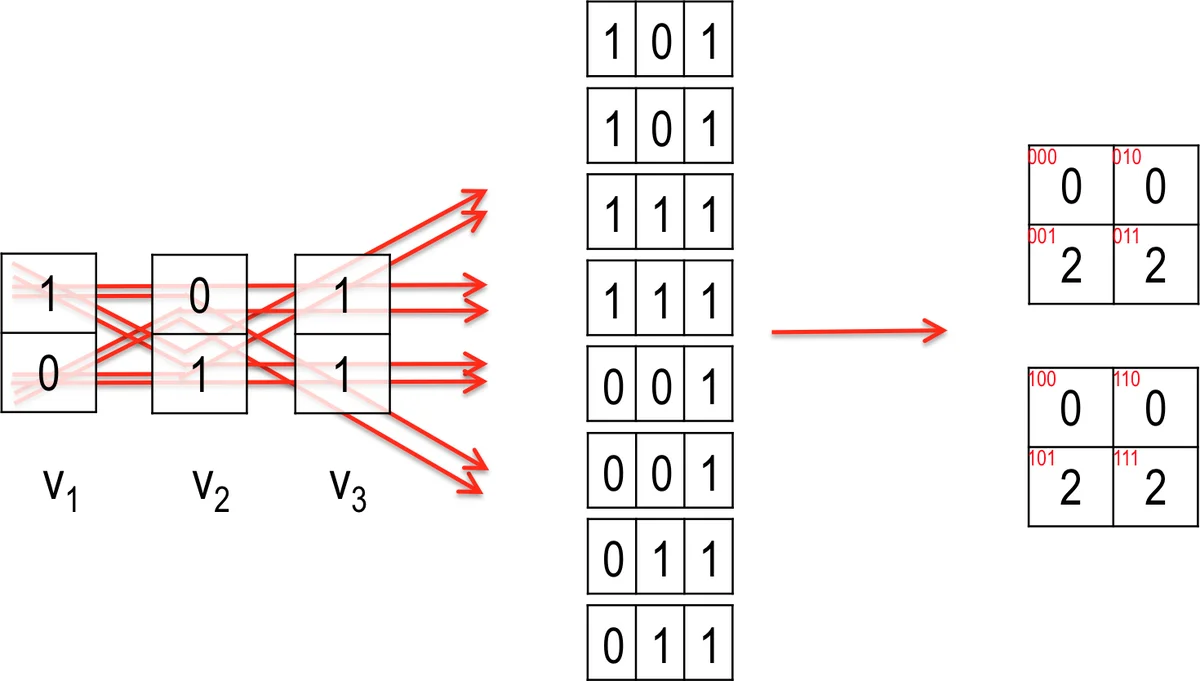
논문은 먼저 CCC의 수학적 정의를 명확히 하고, 2‑way와 3‑way 경우 각각의 연산 복잡도가 O(n_f n_v²)와 O(n_f n_v³)임을 강조한다. 여기서 n_f는 샘플 수, n_v는 SNP 수이다. 핵심 아이디어는 이러한 연산을 기존 고성능 선형대수 라이브러리의 GEMM 커널에 매핑하는 것이다. 2‑way CCC는 각 SNP 쌍에 대해 2×2 빈도표를 누적해야 하는데, 이를 위해 64비트 워드에 64개의 SNP 엔트리를 압축하고, 두 워드에 대해 비트 시프트·OR·AND 연산 후 CUDA 내장 popcnt 함수를 사용해 한 번에 64개의 카운트를 얻는다. 결과는 2개의 double‑precision 값의 mantissa에 25비트씩 저장해 오버플로 없이 최대 2²³‑1개의 샘플을 처리한다. 이 변형된 연산을 mGEMM2라 명명하고, MAGMA의 ZGEMM을 기반으로 구현하였다.
3‑way CCC는 직접적인 GEMM 매핑이 불가능하므로 두 단계로 나눈다. 첫 단계에서는 기준 SNP(v_j)를 기준으로 세 개의 변형 행렬 X_{j,ξ}(ξ=1..3)를 생성한다. 각 X 행렬은 v_j와 원본 행렬 V의 엔트리를 특정 규칙에 따라 재코딩한 것으로, 이는 표 1에 상세히 제시된다. 두 번째 단계에서는 X_{j,ξ}ᵀ와 V 사이에 mGEMM3(변형 GEMM) 연산을 수행해 중간 2‑way 빈도표를 얻고, 이를 조합해 최종 3‑way 빈도표를 복원한다. 이 과정에서도 비트‑레벨 연산과 popcnt를 활용해 메모리 대역폭과 연산량을 최소화한다.
병렬화 측면에서는 SNP 집합을 블록 단위로 분할하고, 각 블록을 노드 수준에서 독립적으로 처리한다. 중복 계산을 방지하기 위해 대칭성을 이용해 i<j<k 형태만 계산하도록 설계했으며, MPI를 이용한 비동기 통신으로 I/O와 계산을 겹치게 함으로써 확장성을 높였다. 구현은 CUDA와 OpenMP를 혼합해 GPU와 CPU를 동시에 활용했으며, Xeon Phi에서는 AVX‑512 기반의 popcnt와 벡터 연산을 이용해 유사한 성능을 달성했다.
성능 평가에서는 ORNL Titan(K80 GPU, 18,688 노드)에서 2‑way CCC에 대해 노드당 3.2 × 10¹¹개의 비교를 초당 수행, 전체 시스템에서는 9 × 10¹⁵개를 달성했다. 강력한 확장성을 보여 1,024노드까지 95% 이상의 효율을 유지했으며, 기존 GPU 전용 구현(GBOOST 등) 대비 10‑30배 빠른 결과를 보고한다. 또한 메모리 사용량을 2‑bit 압축으로 최소화해 대규모 데이터셋(수십억 SNP)도 한 노드 메모리 내에 적재 가능하도록 설계했다. 향후 Summit(IBM Power9 + NVIDIA V100)에서는 double‑precision 연산 성능과 메모리 대역폭이 크게 향상돼 10배 이상의 스루풋(≈9 × 10¹⁶)이 기대된다고 예측한다.
전체적으로 논문은 고차원 유전체 상관 분석에 필요한 계산량을 GPU/Manycore 가속기와 효율적인 알고리즘 설계로 크게 감소시켰으며, 리더십급 슈퍼컴퓨터에서 실용적인 워크플로우를 구현한 점이 가장 큰 공헌이다.
댓글 및 학술 토론
Loading comments...
의견 남기기