클라우드 기반 무서버 실험 관리 도구 Clowdr
초록
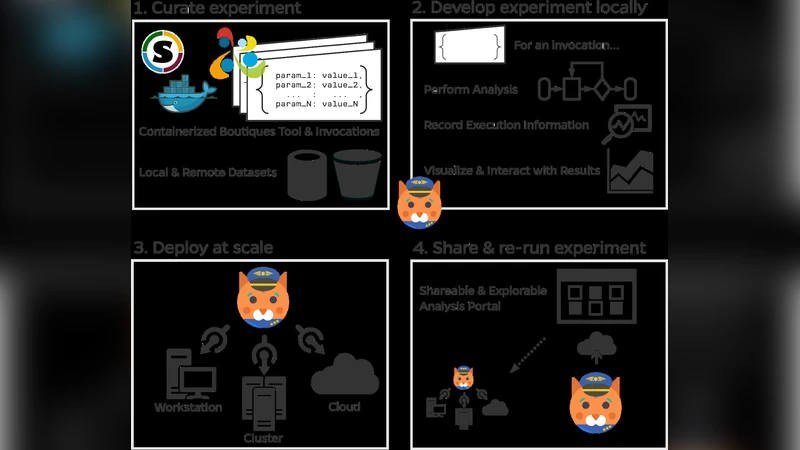
Clowdr는 뇌영상 연구자를 위해 설계된 경량 서버리스 툴로, HPC와 클라우드 환경에서 파이프라인을 손쉽게 실행하고, 실행 메타데이터를 자동으로 기록한다. 기존 웹 포털과 DIY 스크립트 사이의 격차를 메우며, 실험 재현성과 결과 공유를 저비용으로 지원한다.
상세 분석
Clowdr는 현대 신경과학 연구에서 급증하는 데이터 규모와 복잡한 분석 파이프라인을 효율적으로 관리하기 위해 설계된 도구이다. 가장 큰 특징은 “서버리스”라는 개념을 적용해 사용자가 직접 클러스터 관리나 컨테이너 오케스트레이션을 할 필요 없이, 단일 명령어로 작업을 제출하고 모니터링할 수 있다는 점이다. 이를 위해 Clowdr는 두 가지 핵심 표준, 즉 BIDS(Brain Imaging Data Structure)와 Boutiques 툴 설명 언어를 기반으로 인터페이스를 제공한다. BIDS는 입력 데이터의 메타데이터와 디렉터리 구조를 일관되게 정의함으로써 데이터 전처리와 파이프라인 연결을 자동화하고, Boutiques는 각 분석 툴의 입력·출력, 실행 환경을 JSON 스키마로 기술한다. Clowdr는 이러한 표준을 파싱해 실행 명령을 자동 생성하고, 실행 전후에 자동으로 로그, 환경 변수, 컨테이너 이미지 해시 등을 수집한다.
기술적으로 Clowdr는 Python 기반의 CLI와 백그라운드 워커 프로세스로 구성된다. 사용자는 clowdr launch 명령에 BIDS 데이터셋 경로와 Boutiques 툴 정의 파일, 그리고 실행 옵션(예: 슬럼 파라미터, 클라우드 인스턴스 타입)을 전달한다. 워커는 지정된 HPC 스케줄러(SLURM, PBS 등) 혹은 클라우드 API(AWS Batch, Google Cloud Life Sciences)와 통신해 작업을 제출하고, 상태 변화를 실시간으로 폴링한다. 작업이 완료되면, Clowdr는 실행 로그와 함께 “execution record”라는 JSON 문서를 생성한다. 이 문서에는 시작·종료 시각, 사용된 CPU·GPU 자원, 입력·출력 파일 해시, 컨테이너 이미지 SHA256, 그리고 사용자 정의 메타데이터가 포함된다. 이러한 풍부한 메타데이터는 후속 재현성 검증, 오류 추적, 그리고 결과 공유에 핵심적인 역할을 한다.
또한 Clowdr는 결과 공유를 위한 경량 웹 인터페이스를 제공한다. 실행 기록을 HTML 페이지로 변환해 로컬 혹은 정적 웹 서버에 배포하면, 비전문가도 클릭 몇 번으로 파라미터, 로그, 출력 파일을 탐색할 수 있다. 이는 기존의 복잡한 워크플로우 관리 시스템(예: Galaxy, CBRAIN)과 달리 설치·운영 비용을 최소화하면서도 투명성을 유지한다는 장점을 가진다.
보안 측면에서도 Clowdr는 최소 권한 원칙을 적용한다. 클라우드 환경에서는 임시 IAM 역할을 생성해 작업에 필요한 S3 버킷 접근만 허용하고, 작업 종료 시 자동으로 역할을 폐기한다. HPC 환경에서는 사용자의 기존 계정 권한을 그대로 사용하므로 별도 인증 체계가 필요 없다.
한계점으로는 현재 지원되는 스케줄러와 클라우드 서비스가 제한적이며, 대규모 멀티노드 MPI 작업에 대한 최적화가 부족하다는 점이다. 또한 실행 기록의 표준화가 아직 초기 단계이므로, 다른 재현성 플랫폼과의 메타데이터 교환에 추가적인 변환 단계가 필요할 수 있다. 그러나 이러한 제약은 오픈소스 커뮤니티 기반의 플러그인 확장 구조를 통해 점진적으로 해소될 여지가 있다.
전반적으로 Clowdr는 신경과학 연구자가 복잡한 HPC·클라우드 인프라를 직접 다루지 않고도, 표준화된 데이터·툴 정의를 활용해 실험을 자동화하고, 풍부한 메타데이터를 통해 재현성을 확보하며, 결과를 손쉽게 공유할 수 있게 하는 실용적인 중간 계층 솔루션이라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기