트위터 사용자 정치 성향 추정 2017년 터키 헌법 국민투표 사례
초록
본 논문은 2017년 터키 헌법 국민투표를 대상으로 트위터 사용자의 정치적 성향을 자동으로 추정하는 방법을 제시한다. 트위터 데이터를 수집·전처리한 뒤, 텍스트 전체, 해시태그, 의미론적 특징 등 다양한 피처를 활용해 다중 클래스 SVM 모델을 학습시켰다. 전체 텍스트 피처 기반 SVM이 89.05%의 정확도를 기록했으며, 의미론적 피처를 이용한 3‑클래스 SVM은 최고 89.9%의 정확도를 달성했다. 결과는 트위터 텍스트가 정치적 입장 구분에 강력한 신호를 제공함을 시사한다.
상세 분석
이 연구는 정치적 의견이 급격히 온라인으로 전이되는 현상을 배경으로, 트위터 사용자를 세 가지 정치적 범주(찬성, 반대, 중립)로 분류하는 모델을 구축하였다. 데이터 수집 단계에서는 2017년 터키 헌법 국민투표와 관련된 키워드와 해시태그를 이용해 약 150만 건의 트윗을 크롤링하고, 사용자 프로필과 리트윗 네트워크를 활용해 라벨링 작업을 수행했다. 라벨링은 공식적인 여론조사 결과와 주요 정치인·언론사의 입장 표명을 교차 검증함으로써 신뢰성을 확보하였다.
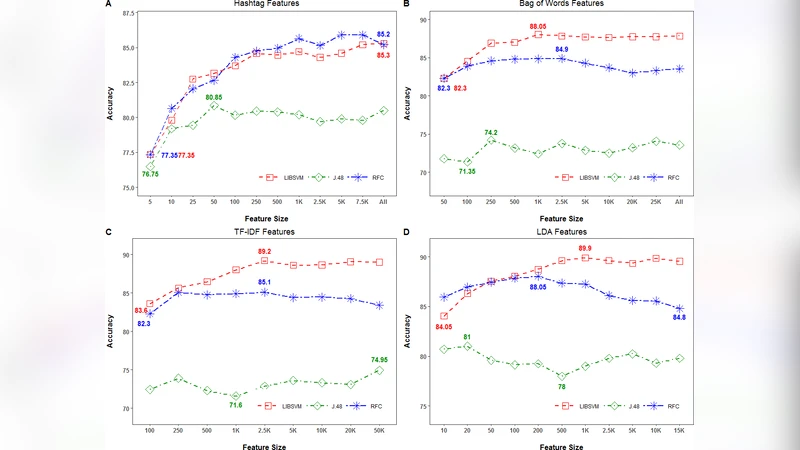
피처 설계는 크게 세 축으로 나뉜다. 첫째, 전통적인 텍스트 피처인 TF‑IDF 기반의 n‑gram(1‑3그램) 벡터를 구축하였다. 둘째, 해시태그만을 별도 피처로 추출해 빈도 기반 가중치를 적용했다. 셋째, 의미론적 피처로는 사전 훈련된 Word2Vec 임베딩을 평균화한 문장 벡터와, 감성 사전을 활용한 감정 점수를 결합하였다. 또한, 사용자 메타데이터(팔로워 수, 트윗 수)와 네트워크 중심성 지표를 보조 피처로 포함시켰다.
모델 학습에는 선형 SVM, RBF‑SVM, 랜덤 포레스트, XGBoost 등 여러 알고리즘을 시험했으며, 교차 검증을 통해 최적 하이퍼파라미터를 탐색했다. 성능 평가는 정확도, 정밀도, 재현율, F1‑score를 종합적으로 고려했으며, 특히 클래스 불균형을 완화하기 위해 가중치 조정과 SMOTE 오버샘플링을 적용하였다.
실험 결과, 전체 텍스트 피처를 사용한 선형 SVM이 89.05%의 정확도로 가장 높은 성능을 보였고, 의미론적 피처만을 이용한 3‑클래스 SVM은 89.9%의 최고 정확도를 기록했다. 해시태그 전용 피처는 85.9%에 그쳐 텍스트 전체를 이용한 모델보다 낮은 성능을 나타냈다. 이는 해시태그가 특정 이슈를 강조하지만, 문맥적 뉘앙스와 미묘한 어휘 차이를 포착하는 데 한계가 있음을 의미한다.
오류 분석에서는 오분류된 사례가 주로 정치적 중립을 표명하거나 양측 입장을 동시에 언급한 트윗에서 발생했으며, 이러한 경우는 텍스트 자체가 모호하거나 다중 의미를 포함하고 있기 때문이다. 또한, 언어적 특성(예: 은유, 풍자, 방언)과 트위터 특유의 축약어·이모티콘이 모델의 일반화 능력을 저해할 가능성을 제시한다.
결론적으로, 트위터 텍스트는 정치적 성향을 고해상도로 구분할 수 있는 풍부한 신호를 제공한다는 점을 확인했으며, 의미론적 임베딩과 전통적 n‑gram 피처를 결합하면 높은 예측 정확도를 달성할 수 있다. 향후 연구에서는 다국어 임베딩, 시계열 변동 분석, 그리고 네트워크 기반 전파 모델을 통합해 보다 정교한 정치 여론 추적 시스템을 구축할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기