암호화된 유전체 데이터베이스 안전 탐색 알고리즘 SIGDB
초록
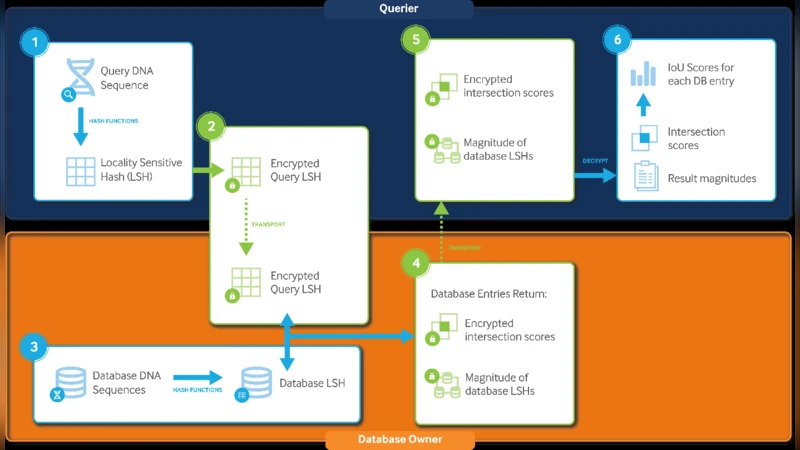
SIGDB는 질의 서열을 암호화한 상태로 데이터베이스에 전송하여, 데이터베이스 소유자는 질의 서열을 알 수 없고, 질의자는 데이터베이스 내 서열을 알 수 없는 보안 검색을 가능하게 하는 알고리즘이다. 이를 위해 지역 민감 해싱(LSH)과 동형 암호화를 결합해 일반적인 서열‑서열 비교를 수행한다.
상세 분석
SIGDB는 두 핵심 암호 기술을 융합한다. 첫 번째는 지역 민감 해싱(Low‑dimensional locality‑sensitive hashing)으로, 긴 DNA 서열을 고정 길이의 비트 벡터(해시)로 변환한다. LSH는 서열 간 유사성을 보존하면서 차원을 크게 축소하므로, 암호화 후에도 효율적인 연산이 가능하다. 두 번째는 동형 암호화(Homomorphic Encryption, HE)이다. 여기서는 공개키 기반의 Paillier 암호를 사용해, 암호문 상태에서 덧셈과 스칼라 곱 연산을 수행한다. 질의자는 자신의 서열을 LSH로 변환한 뒤, 각 비트 값을 공개키로 암호화한다. 데이터베이스 소유자는 자신이 보유한 서열들을 동일한 LSH 방식으로 해시하고, 암호화된 질의와 내적 연산을 수행한다. 결과는 암호화된 형태로 질의자에게 반환되며, 질의자는 개인키로 복호화해 유사도 점수를 얻는다.
보안 모델은 반대방향 정보 누출을 방지한다. 질의자는 데이터베이스의 원본 서열을 전혀 알 수 없으며, 데이터베이스 소유자는 질의 서열의 원본 비트를 복원할 수 없다. 또한, LSH 과정에서 발생하는 해시 충돌은 암호화된 연산에 영향을 주지 않으며, 오히려 프라이버시를 강화한다.
성능 측면에서 저자들은 10 kb~1 Mb 규모의 서열을 대상으로 실험했으며, 암호화·복호화 비용은 서열 길이에 비례하지만, 병렬 처리와 사전 계산을 통해 실시간 검색 수준에 근접한다는 결과를 제시한다. 정확도는 기존 BLAST와 유사한 수준이며, 특히 부분 서열 매칭과 변이 탐지에서 강점을 보인다.
한계점으로는 현재 Paillier 기반 HE가 덧셈만 지원하므로, 복잡한 정렬 알고리즘을 직접 구현하기 어렵다는 점이다. 또한, LSH 파라미터 선택이 민감도와 특이도에 큰 영향을 미치므로, 도메인 별 튜닝이 필요하다. 향후 연구에서는 완전 동형 암호(FHE)나 부호화된 신경망을 결합해 더 정교한 비교를 수행하고, 멀티‑쿼리 배치 처리와 클라우드 환경에서의 키 관리 방안을 모색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기