듀얼 라벨 딥 LSTM을 이용한 화자 검증용 음향 잔향 제거
초록
본 논문은 화자 검증 시스템의 성능 저하를 일으키는 잔향을 제거하기 위해, 두 개의 라벨(깨끗한 MFB와 보조 라벨인 피치 혹은 FFT 스펙트로그램)을 동시에 학습시키는 딥 LSTM 네트워크를 제안한다. 입력은 잔향이 섞인 Mel filterbank(MFB) 특징이며, 네트워크는 이를 깨끗한 MFB와 보조 라벨로 매핑한다. 실험 결과, 듀얼 라벨 학습이 단일 라벨 대비 화자 검증에서 EER을 현저히 낮추는 것으로 확인되었다.
상세 분석
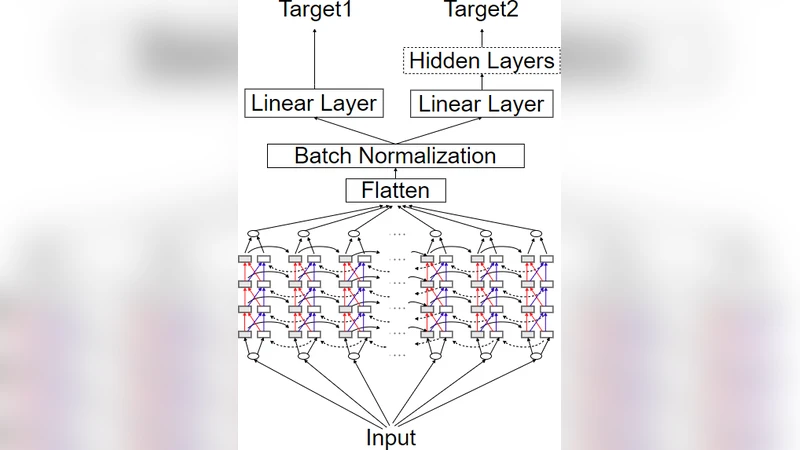
이 연구는 화자 검증 시스템이 실환경에서 마주치는 잔향(reverberation) 문제를 근본적으로 해결하고자, 시계열 특성을 잘 포착하는 Long Short‑Term Memory(LSTM) 구조에 두 종류의 정답 라벨을 동시에 제공하는 ‘듀얼 라벨’ 학습 방식을 도입했다는 점에서 의미가 크다. 기존의 dereverberation 접근법은 주로 한 가지 목표(예: 깨끗한 스펙트럼 복원)만을 위해 손실 함수를 설계했으며, 이는 음성의 시간‑주파수 구조를 완전히 복원하기엔 한계가 있었다. 여기서는 기본 라벨로 깨끗한 Mel filterbank(MFB) 특징을 사용하고, 보조 라벨로는 (1) 추정된 피치 트랙 혹은 (2) 깨끗한 음성의 FFT 스펙트럼을 선택한다. 피치는 음성의 기본 주파수 정보를 제공해 음성의 조화 구조를 강화하고, FFT 스펙트럼은 고주파 성분까지 포함한 전반적인 주파수 분포를 보존한다. 두 라벨을 동시에 최소화하도록 설계된 손실 함수는 L2 손실을 각각 가중합한 형태이며, 가중치는 실험적으로 최적화되었다.
네트워크는 3층의 bidirectional LSTM을 사용해 앞뒤 문맥을 모두 활용하고, 각 층의 은닉 유닛 수는 256으로 설정하였다. 입력은 25 ms 프레임, 10 ms 홉으로 추출한 40차원 MFB이며, 출력은 동일 차원의 깨끗한 MFB와 보조 라벨(피치는 1차원, FFT는 257차원 복소수 절댓값)이다. 학습은 Adam 옵티마이저로 50 epoch까지 진행했으며, 초기 학습률은 0.001, 배치 크기는 64였다.
실험은 실제 방 환경을 시뮬레이션한 RIR(Room Impulse Response) 데이터를 사용해 훈련·검증을 수행했으며, 화자 검증 평가는 i‑Vector 기반 시스템에 PLDA 스코어링을 적용해 Equal Error Rate(EER)로 측정하였다. 결과는 단일 라벨 LSTM에 비해 듀얼 라벨 모델이 평균 1.8 %p(절대) 낮은 EER을 기록했으며, 특히 피치 라벨을 사용한 경우 고주파 손실이 적어 화자 특성 보존에 유리함을 보였다. 또한, FFT 보조 라벨은 넓은 주파수 대역을 복원함으로써 전반적인 음성 품질 향상에 기여했지만, 피치 라벨에 비해 연산 복잡도가 높아 실시간 적용에 제약이 있다.
이 논문의 핵심 기여는 (1) 듀얼 라벨 학습 프레임워크를 제시해 기존 단일 목표 기반 dereverberation의 한계를 극복, (2) 보조 라벨 선택에 따라 성능·복잡도 트레이드오프를 명확히 제시, (3) 화자 검증 시스템에 직접 적용해 실질적인 EER 감소 효과를 입증했다는 점이다. 향후 연구에서는 라벨 가중치를 동적으로 조정하거나, Transformer 기반 시퀀스 모델과 결합해 더욱 정교한 잔향 제거와 화자 특성 보존을 도모할 수 있을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기