시각·청각 융합 딥러닝 기반 화자 독립 음성 분리 마스크 추정
본 논문은 청각과 시각 정보를 동시에 활용하는 하이브리드 딥러닝 모델을 제안한다. 스택형 LSTM과 Convolution‑LSTM을 결합한 구조로, 잡음에 강인한 입술 영상 특징과 스펙트럼 특징을 시간적 맥락 속에서 융합하여 이상적인 이진 마스크(IBM)를 추정한다. 화자 독립·종속 두 시나리오에서 기존의 오디오‑전용·비디오‑전용 모델을 능가하는 마스크 정확도(최대 95.5 %)와 PESQ 향상(최대 2.34)을 기록하였다.
저자: M, ar Gogate, Ahsan Adeel
본 논문은 인간 청각 피질이 청각과 시각 정보를 통합해 선택적 주의를 수행한다는 생리학적 현상을 모방한, 화자 독립적인 음성 분리 시스템을 제안한다. 기존의 통계적 잡음 추정 방법과 CASA 기반 마스크 추정 방법은 각각 잡음 왜곡과 복잡한 파라미터 설정이라는 한계를 가지고 있었으며, 특히 비정상 잡음이나 새로운 화자에 대한 일반화가 어려웠다. 이를 극복하기 위해 저자는 오디오와 비주얼 두 모달리티의 특징을 동시에 학습하는 하이브리드 딥러닝 구조를 설계하였다.
**시스템 개요**는 크게 세 단계로 구성된다. 첫 번째 단계는 전처리 단계로, 16 kHz로 샘플링된 음성 신호를 80 ms 프레임(622‑bin 파워 스펙트럼)으로 변환하고, 영상에서는 25 fps로 촬영된 GRID 코퍼스 영상을 Viola‑Jones 기반 입술 검출기와 트래커를 이용해 92 × 50 픽셀 ROI를 추출한다. 비디오 프레임은 오디오와 동일한 시간 해상도를 맞추기 위해 3배 업샘플링한다.
두 번째 단계는 **특징 추출**이다. 오디오 서브넷은 5개의 연속 프레임을 입력으로 받아 2‑layer 스택 LSTM(각 1024 셀)으로 처리한다. 각 LSTM 레이어 뒤에 0.2의 드롭아웃을 적용해 과적합을 방지하고, 마지막 LSTM 출력 1024‑dim을 오디오 특징으로 사용한다. 비주얼 서브넷은 4개의 Conv‑ReLU 레이어와 4개의 Max‑Pool 레이어(필터 수 32, 64, 64, 128)를 거쳐 공간적 특징을 추출한 뒤, 1024‑cell LSTM에 입력해 시각적인 시간적 흐름을 모델링한다. 최종적으로 1024‑dim 시각 특징을 얻는다.
세 번째 단계는 **멀티모달 융합 및 마스크 추정**이다. 두 1024‑dim 특징을 단순 연결해 2048‑dim 벡터를 만든 뒤, 2‑layer MLP(첫 레이어 1024‑ReLU, 두 번째 레이어 622‑Sigmoid)로 매핑한다. 출력은 각 T‑F 유닛에 대한 마스크 확률이며, 별도의 임계값 설정 없이 바로 사용한다. 이 구조는 early‑fusion(특징 연결)과 late‑fusion(MLP) 방식을 동시에 활용해 두 모달리티의 상보적 정보를 최대한 보존한다.
**데이터와 실험 설계**는 GRID 코퍼스의 5명 화자(각 1000개 문장)와 CHiME‑3에서 제공된 비정상 잡음(버스, 카페, 거리, 보행자)을 -12 dB부터 6 dB까지 6 dB 간격으로 혼합한 데이터를 사용한다. 화자 독립 실험에서는 3명(1, 6, 7)으로 학습하고, 남은 2명(15, 26)을 테스트했다. 화자 종속 실험에서는 모든 5명을 학습에 포함하고, 2명을 테스트에 사용했다. 전체 데이터의 80 %를 훈련, 20 %를 테스트에 할당했으며, 훈련 데이터는 다시 20 %를 검증용으로 분리했다.
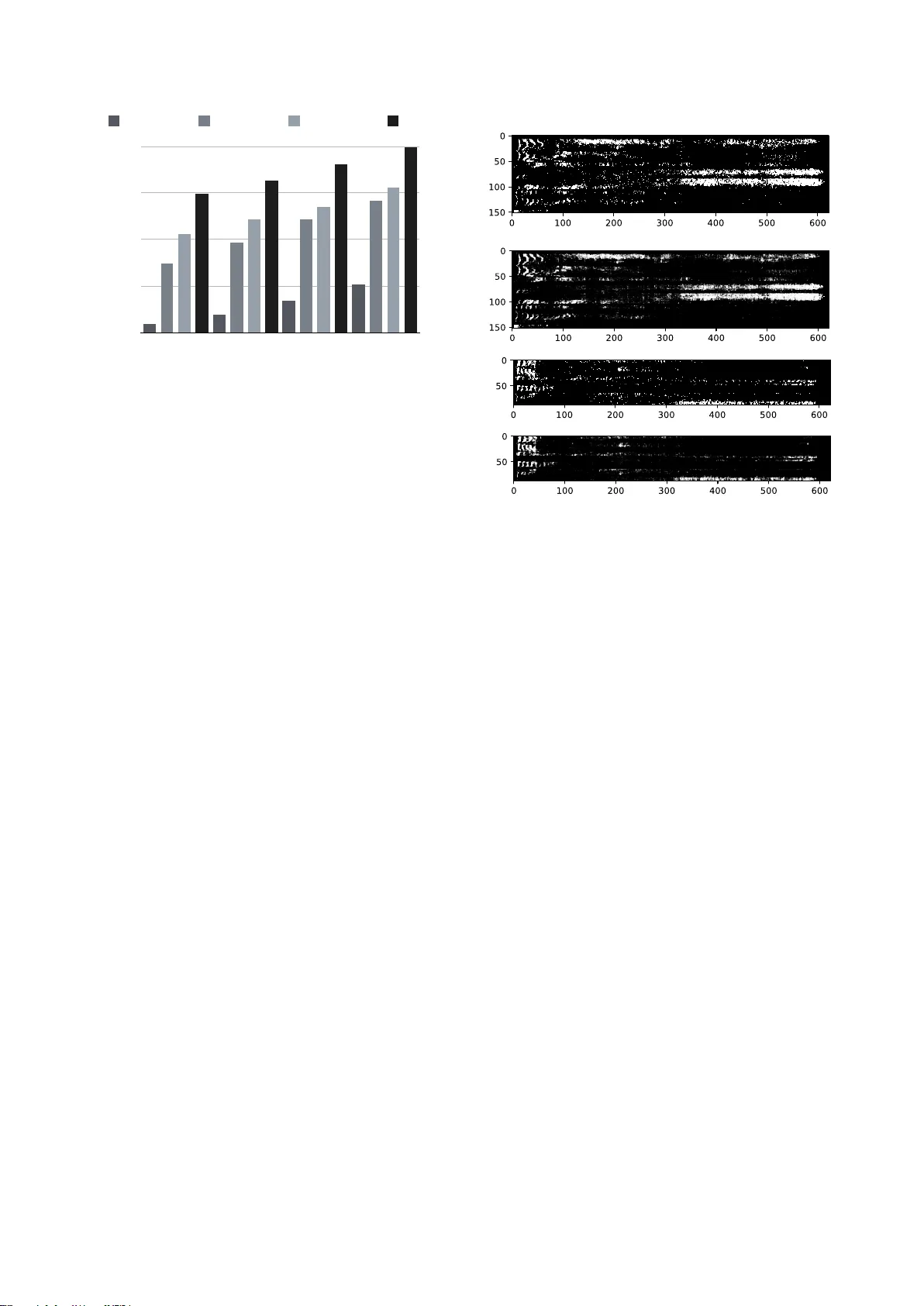
**성능 평가**는 두 가지 지표로 수행되었다. 첫째는 T‑F 마스크 분류 정확도이며, AV 모델은 -12 dB에서 95.5 %, -6 dB에서 94.8 %, 0 dB에서 92.1 %의 정확도를 기록했다. 이는 오디오‑전용(최대 96.7 %)과 비디오‑전용(최대 92.8 %)보다 일관적으로 높은 성능을 보였으며, 특히 저 SNR 구간에서 시각 정보가 잡음에 대한 강인성을 제공함을 확인할 수 있었다. 둘째는 PESQ(Perceptual Evaluation of Speech Quality) 점수이다. AV 모델은 -12 dB에서 1.87, -6 dB에서 2.05, 0 dB에서 2.17, 6 dB에서 2.34를 달성했으며, 이는 IBM(이상적인 마스크)과 거의 근접한 수준이다. 반면 오디오‑전용은 1.61~2.34, 비디오‑전용은 1.09~1.51에 머물렀다.
**주요 기여**는 다음과 같다. (1) 오디오와 비주얼 특징을 각각 LSTM과 Conv‑LSTM으로 최적화해 시간적·공간적 정보를 효과적으로 추출, (2) 두 특징을 고차원 벡터로 결합해 MLP 기반 마스크 추정기로 전달, (3) 화자 독립 시나리오에서도 높은 마스크 정확도와 PESQ 향상을 달성, (4) 기존 연구에서 주로 다루던 화자 종속 모델을 넘어 실제 서비스 환경에 가까운 화자 독립 모델을 제시.
**제한점 및 향후 연구**는 다음과 같다. GRID 코퍼스는 문법이 고정되고 입술 움직임이 명확해 실험 결과가 과대평가될 가능성이 있다. 따라서 더 다양하고 자연스러운 대화 데이터를 사용해 일반화 성능을 검증할 필요가 있다. 또한 현재는 5개의 과거 프레임만을 사용했으나, 장기 의존성을 포착하기 위해 Transformer 기반 어텐션 메커니즘을 도입하거나, 멀티스케일 CNN을 결합해 시각 특징의 해상도를 높이는 방안을 고려할 수 있다. 마지막으로 실시간 처리와 메모리 효율성을 개선하기 위해 경량화 모델(예: MobileNet‑V2 기반 비주얼 서브넷)과 지연 최소화 기법을 연구할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기