디지털 도시 감시의 다층적 접근
초록
본 연구는 뉴욕시의 6가지 디지털 데이터(택시, 지하철, Citi Bike, 모바일 앱, 트위터, 311 서비스 요청)를 활용해 공간·시간적 활동 분포를 비교한다. 각 데이터가 주거·근무 인구와 어떻게 연관되는지 분석하고, 인구·인구통계학적 특성에 대한 편향을 정량화한다. 다층 모델을 구축해 도시 구역화와 사회경제적 변수 예측에 적용함으로써 단일 데이터만 사용할 때보다 높은 정확도를 보인다.
상세 분석
이 논문은 디지털 센싱이 제공하는 다양한 활동 데이터를 통합해 도시 동태를 다층적으로 해석한다. 데이터는 2017년 7월 한 달간 뉴욕시 263개 택시 구역에 매핑되었으며, 각 레코드는 시작·종료 위치와 시간 정보를 포함한다. 공간 전처리 단계에서 모든 데이터셋을 동일한 격자(택시 구역)로 변환해 비교 가능하도록 하였고, 시간 전처리에서는 하루 8개의 3시간 구간을 7일 동안 평균해 56차원의 주간 타임라인을 구축하였다.
공간적 상관관계 분석에서는 Pearson 상관계수를 이용해 6개 활동과 주거·근무 인구 분포 간의 연관성을 평가했다. 311과 모바일 데이터는 주거 인구와 높은 상관을 보였으며, 트위터·택시·지하철·Citi Bike은 근무 인구와 더 강하게 연결된다. 이는 각 서비스가 이용되는 장소와 목적이 다름을 시사한다.
시간적 패턴에서는 모든 데이터가 주간 주기를 보였지만, 교통 데이터는 평일에 두 개의 피크(출퇴근) 를, 311·모바일·트위터는 단일 피크를 나타냈다. 특히 모바일과 트위터의 타임라인은 거의 일치해 실시간 소셜 활동이 유사한 일일 리듬을 가진다는 점을 확인했다.
공간 분포를 근무·주거 인구의 선형 결합으로 모델링해 균형 계수 β를 추정했다. β≈0인 311은 주거 중심, β>0.7인 교통 데이터와 트위터는 근무 중심임을 정량화했다. 또한 β는 시간에 따라 변동해 주중에는 높고 주말에는 낮아지는 일일·주간 주기성을 보였다.
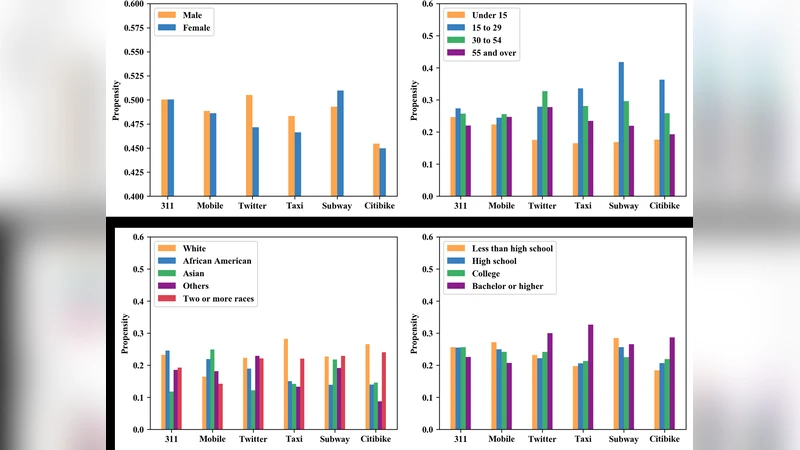
인구통계학적 편향을 설명하기 위해 연령·성별·인종·교육 수준별 ‘활동 인구’를 구성하고, L2 정규화를 적용한 회귀로 각 그룹의 활동 선호도 θ를 추정했다. 결과는 15‑29세와 30‑59세 연령층이 교통 데이터에 높은 θ를 보이며, 고학력층이 트위터·택시·Citi Bike 이용에 더 큰 선호를 나타낸다.
클러스터링 단계에서는 각 데이터의 56차원 타임라인을 L1 정규화 후 k‑means(k=5)로 구역을 구분했다. 개별 데이터별 클러스터는 관광지, 저밀도 주거, CBD 등 의미 있는 공간 패턴을 드러냈으며, 6개 데이터를 모두 결합한 클러스터는 더욱 일관된 사회경제적 특성을 반영했다. 군집 품질 평가는 Adjusted Rand Index와 Silhouette 점수를 사용했으며, 전체 결합 클러스터가 Silhouette 점수에서 최고를 기록해 다층 접근의 효용을 입증했다.
마지막으로, 각 데이터의 주간 타임라인을 독립 변수로 사용해 인구소득, 교육 수준 등 사회경제적 지표를 회귀 모델링했다. 단일 데이터보다 다층 모델이 예측 정확도가 크게 향상되었으며, 특히 311과 교통 데이터의 결합이 가장 높은 설명력을 제공했다.
전반적으로 이 연구는 디지털 도시 센싱이 제공하는 다중 데이터 소스의 상호 보완성을 정량적으로 입증하고, 공간·시간적 편향을 해소하기 위한 통계적 프레임워크를 제시한다. 다층 모델은 도시 계획, 재난 대응, 사회경제적 정책 설계 등에 활용될 수 있는 강력한 도구임을 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기