투명한 에너지 모델링을 위한 전력플랜트 데이터 품질 검증
초록
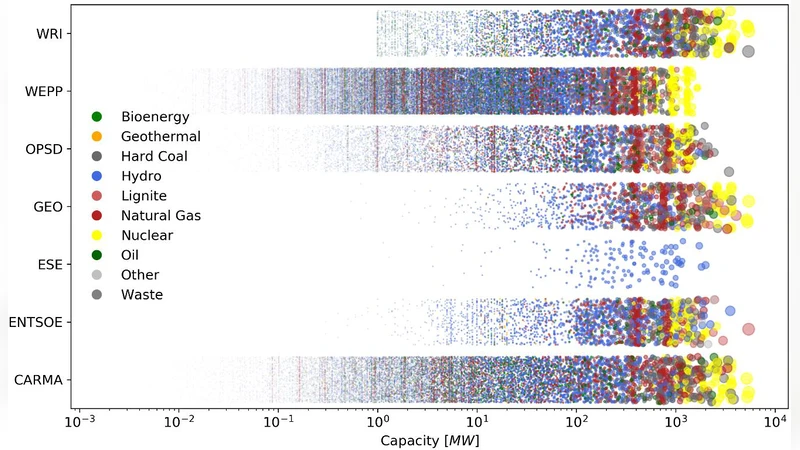
본 논문은 공개 전력플랜트 데이터베이스와 상용 데이터베이스를 비교·통합하는 파이썬 기반 도구 “powerplantmatching”(PPM)을 소개한다. 오픈 데이터만으로 만든 데이터셋은 용량 면에서는 상용 데이터와 유사하지만, 연도·위치·연료 유형 등 세부 항목에서는 품질 차이가 나타난다. 특히 가동 연도 정보는 상용 데이터가 없을 경우 품질이 크게 저하된다는 점을 강조한다.
상세 분석
본 연구는 에너지 모델링에서 데이터 투명성과 재현성을 확보하기 위한 구체적 방법론을 제시한다. 먼저 기존에 공개된 전력플랜트 데이터베이스(예: Global Power Plant Database, World Resources Institute 등)와 상용 데이터베이스(예: BloombergNEF, IEA 등)를 수집하고, 각 데이터베이스가 제공하는 변수(설비 용량, 연료 종류, 지리 좌표, 가동 연도 등)의 형식과 스키마가 상이함을 확인한다. 이를 해결하기 위해 저자들은 파이썬 기반 오픈소스 패키지 “powerplantmatching”(PPM)를 개발하였다. PPM은 (1) 데이터 정제 단계에서 중복 레코드 제거, 결측값 보완, 단위 통일 등을 수행하고, (2) 표준화 단계에서 국가 코드, 연료 코드, 좌표 체계 등을 국제 표준에 맞게 매핑한다. 특히, 레코드 매칭 알고리즘은 다중 기준(용량 차이, 지리적 거리, 연료 유형 일치 여부 등)을 가중치로 적용해 동일 설비를 식별한다.
연구자는 두 가지 매칭 시나리오를 설정하였다. 첫 번째는 오픈 데이터베이스만을 이용한 매칭이며, 두 번째는 오픈 데이터에 상용 데이터베이스를 추가한 매칭이다. 두 시나리오 모두 전체 설비 수, 국가별 설비 분포, 연료별 용량 비중을 비교하였다. 결과적으로 용량 총합과 주요 연료별 비중은 두 데이터셋 간 차이가 미미했으나, 가동 연도와 좌표 정확도에서는 현저한 차이가 발견되었다. 특히, 오픈 데이터만으로는 연도 정보가 누락되거나 부정확한 경우가 다수였으며, 이는 시간에 민감한 모델(예: 연도별 탈탄소 경로 시뮬레이션)에서 큰 오차를 초래할 수 있다. 반면, 상용 데이터베이스를 포함하면 연도 데이터의 완전성이 85 % 이상으로 크게 향상되었다.
또한, 데이터 품질 평가 지표로는 (①) 데이터 커버리지(전체 설비 대비 포함 비율), (②) 변수 완전성(결측값 비율), (③) 일관성(동일 설비에 대한 다중 출처 간 값 차이) 등을 사용하였다. 오픈 데이터만을 활용한 경우 커버리지는 약 70 % 수준이었으며, 연료 유형 일치율은 92 %였지만, 연도 완전성은 48 %에 불과했다. 상용 데이터를 추가했을 때는 커버리지가 88 %로 상승하고, 연도 완전성은 84 %로 크게 개선되었다.
이러한 결과는 에너지 모델링 연구자가 데이터 출처와 품질을 명시적으로 검증하고, 가능한 경우 상용 데이터와 결합하는 것이 모델 신뢰성을 높이는 데 필수적임을 시사한다. 또한, PPM 도구는 재현 가능한 워크플로우를 제공함으로써 연구 커뮤니티 내 데이터 공유와 검증을 촉진한다. 향후 연구에서는 자동화된 품질 점수 체계와 머신러닝 기반 매칭 알고리즘을 도입해 데이터 통합 효율성을 더욱 향상시킬 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기