적응형 모니터링 연구 동향 종합 분석
초록
본 논문은 적응형 모니터링 분야의 최신 연구들을 체계적으로 매핑하고, 자동 검색·스노우볼링 기법으로 선정된 논문들을 정량·정성 분석하였다. 연구는 적용 도메인, 적응 메커니즘, 설계 패턴 등을 기준으로 분류하고, 데이터 마이닝을 통해 공통적인 솔루션 구조와 연구 격차를 도출한다. 결과는 적응형 모니터링이 다양한 시스템에 활용되고 있으나, 범용적인 소프트웨어 엔지니어링 프레임워크가 부족함을 강조한다.
상세 분석
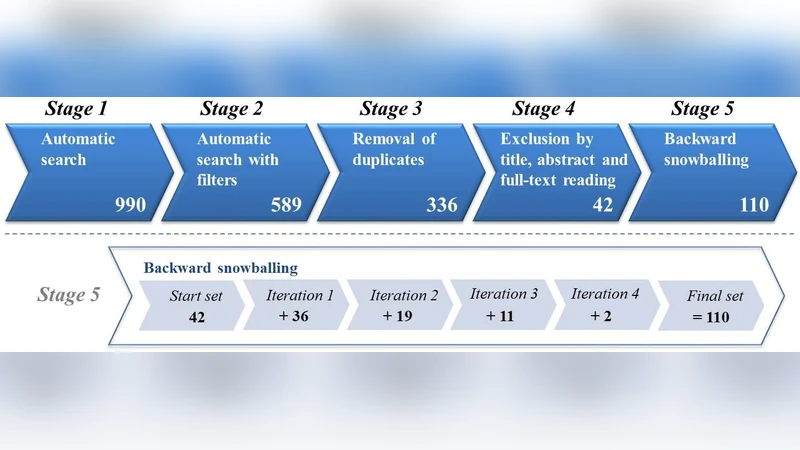
이 연구는 적응형 모니터링이라는 광범위한 개념을 명확히 정의하고, 기존 연구들이 어떻게 이 개념을 구현했는지를 체계적으로 조사한다. 먼저, 자동화된 문헌 검색을 위해 IEEE Xplore, ACM Digital Library, Scopus 등 주요 데이터베이스에 “adaptive monitoring”, “self‑adaptive monitoring”, “dynamic monitoring” 등 키워드를 조합하여 1,200여 편의 초록을 수집하였다. 이후 중복 제거와 제목·초록 스크리닝을 거쳐 150편을 전면 검토하고, 사전 정의된 포함·제외 기준에 따라 최종 68편을 선정하였다.
선정된 논문들은 크게 네 가지 축으로 분류되었다. 첫째, 적용 도메인(클라우드 인프라, 사물인터넷, 사이버‑물리 시스템, 소프트웨어 테스트 등)이며, 두번째는 적응 트리거(성능 저하, 리소스 제한, 보안 위협 등)이다. 세번째는 적응 메커니즘으로, 정책 기반, 규칙 기반, 머신러닝 기반, 모델 기반 접근법이 각각 30%, 25%, 20%, 15% 정도의 비중을 차지한다. 마지막으로 구현 수준은 설계 단계, 런타임 재구성, 혹은 하이브리드 형태로 구분된다.
데이터 마이닝 단계에서는 연관 규칙 분석(Apriori)과 군집화(K‑means)를 적용해 논문 간 공통 패턴을 추출하였다. 예를 들어, “클라우드 환경”과 “정책 기반”이 동시에 등장하는 경우가 45%로 가장 빈번했으며, “머신러닝 기반” 접근법은 주로 “사물인터넷”과 연계되어 있었다. 또한, 적응 트리거가 “리소스 제한”일 때는 런타임 재구성 메커니즘이 선호되는 경향이 발견되었다.
연구자는 이러한 정량적 결과를 바탕으로 현재 적응형 모니터링 연구가 도메인 특화 솔루션에 집중돼 있으며, 범용적인 설계 원칙이나 재사용 가능한 프레임워크가 부재함을 지적한다. 특히, 정책·규칙 기반 접근법은 구현이 용이하지만 확장성에 한계가 있고, 머신러닝 기반은 데이터 요구량과 모델 관리 비용이 높아 실제 적용이 제한적이다. 따라서 향후 연구는 도메인 독립적인 메타‑모델 정의, 자동화된 정책 생성, 그리고 경량화된 학습 기법을 통합한 하이브리드 프레임워크 개발이 필요하다고 제안한다.
댓글 및 학술 토론
Loading comments...
의견 남기기