프레임 정렬 방식 비교와 KL 기반 내용 검증을 활용한 GMM 기반 디지털 프롬프트 스피커 인증
초록
본 논문은 디지털 프롬프트 환경에서 GMM 기반 스피커 인증에 사용되는 프레임 정렬 방법을 비교한다. HMM 기반 강제 정렬과 DNN 기반 후방 정렬을 동일한 음소 단위와 PGMM 구조로 구현하고, 두 정렬의 특성을 활용해 텍스트 일치 여부를 KL 발산 점수로 빠르게 판단한다. 실험 결과, 두 정렬 방식은 인증 정확도에서 동등한 성능을 보이며, 제안된 KL 기반 내용 검증이 잘못된 패스프레이즈를 효과적으로 차단한다.
상세 분석
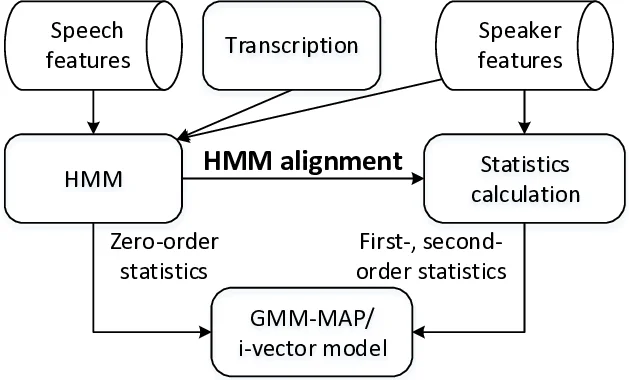
이 연구는 텍스트‑프롬프트 스피커 인증, 특히 숫자 문자열을 입력받는 RSR2015 Part‑3 과제에 초점을 맞춘다. 기존 GMM‑UBM 기반 시스템에서 프레임 정렬은 성능 좌우의 핵심 요소이며, 정렬 품질에 따라 동일 음소에 대한 통계가 얼마나 정확히 축적되는지가 결정된다. 저자들은 두 가지 정렬 방식을 동일한 음소 집합(10개의 숫자와 무음) 위에 구축한다. 첫 번째는 전통적인 HMM‑Viterbi 혹은 Forward‑Backward(FB) 강제 정렬이다. 여기서는 사전에 주어진 텍스트와 일치한다는 가정 하에, 각 프레임이 가장 가능성이 높은 상태에 할당되며, 상태 내부의 GMM 혼합 성분까지 세분화한다. 두 번째는 DNN 기반 정렬로, DNN은 4개의 완전 연결 층(각 512노드)과 33개의 출력(각 상태)으로 구성되며, HMM 정렬을 라벨로 사용해 학습된다. DNN은 로컬 음향 특징에만 의존하므로 전사 오류에 강인하지만, 잡음에 민감한 단점이 있다. 두 정렬 모두 PGMM(Phonetic GMM) 구조를 도입해 각 상태를 16개의 혼합 Gaussian으로 모델링한다. 이는 상태 수가 적은 디지털 프롬프트 환경에서도 충분한 표현력을 확보한다는 장점이 있다.
성능 비교는 GMM‑MAP 적응과 i‑vector 추출 두 파이프라인에서 수행된다. GMM‑MAP에서는 HMM 정렬을 통해 얻은 Baum‑Welch 통계(N, F, Σ)를 이용해 평균을 MAP 방식으로 업데이트하고, 로그우도비를 스코어링한다. i‑vector에서는 동일 통계를 기반으로 총변동(total variability) 공간을 학습하고, 400 차원의 i‑vector를 추출한 뒤 LDA, 길이 정규화, PLDA로 최종 점수를 산출한다. 실험 결과, HMM 정렬과 DNN 정렬 모두 TC‑IC(정확한 텍스트·임포스터) 시나리오에서 거의 동일한 EER과 minDCF를 기록했으며, 이는 정렬 품질이 충분히 높아 스피커 모델링에 큰 차이를 만들지 않음을 시사한다.
가장 혁신적인 부분은 두 정렬 간의 차이를 이용한 내용 검증이다. HMM 정렬은 전사와 일치할 때만 정확한 시퀀스를 제공하고, 텍스트가 틀리면 강제 정렬이 잘못된 경로를 선택한다. 반면 DNN 정렬은 전사와 무관하게 음향 기반 확률을 제공한다. 저자들은 각 프레임 t에 대해 HMM과 DNN의 포스트리어 확률 γ_HMM(p,t), γ_DNN(p,t) (p는 디지털 프롬프트의 한 숫자에 해당하는 음소 집합) 를 구하고, KL 발산
KL = (1/T) Σ_t Σ_p γ_HMM(p,t) log
댓글 및 학술 토론
Loading comments...
의견 남기기