코드 안 제로데이 취약점 발견 시점과 공급망 공격의 시간표
초록
본 연구는 오픈소스 프로젝트에서 코드 라인이나 파일이 수정되는 빈도를 분석해, 숨겨진 제로데이와 명백한 취약점이 실제 코드에서 발견될 확률을 추정한다. 라인‑단위와 파일‑단위 수정 모델을 구축하고, Firefox, Linux 커널, glibc 87개 버전에 걸친 10억 개 이상의 라인 데이터를 이용해 발견 가능성의 상한·하한을 제시한다.
상세 분석
이 논문은 제로데이 취약점의 “수명”을 코드 수준에서 정량화하려는 시도로, 두 가지 가정을 설정한다. 첫째, 고도로 은폐된 취약점은 해당 라인이 직접 검토될 때만 발견될 수 있다고 보고, 이를 “라인‑레벨 발견 가능성”이라 명명한다. 둘째, 명백한 취약점은 파일 전체가 검토되면 발견될 수 있다고 가정해 “파일‑레벨 발견 가능성”을 정의한다. 이러한 가정은 실제 보안 감사에서 흔히 관찰되는 “코드 리뷰 범위”와 일치한다는 점에서 실용적이다.
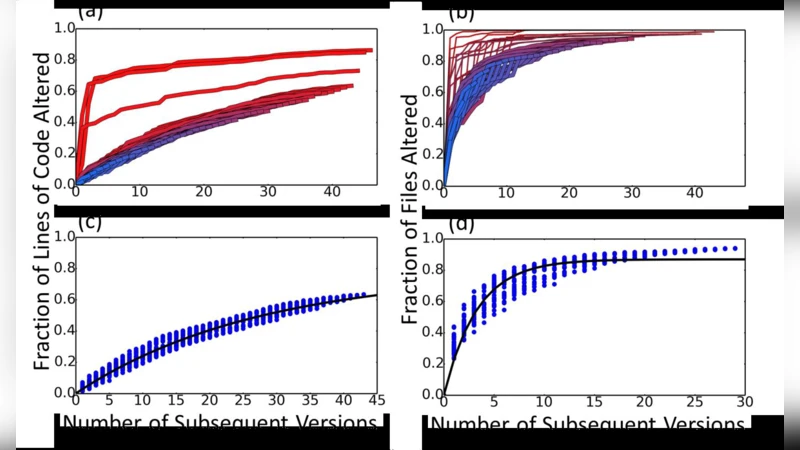
연구자는 세 개의 대표적인 오픈소스 프로젝트—Mozilla Firefox, GNU/Linux 커널, glibc—의 버전 간 변화를 추적한다. 각 버전마다 소스 트리를 파싱해 파일·라인의 추가·삭제·수정을 기록하고, 전체 87개 버전(2000년대 초부터 최신까지)에서 1,032,487,639개의 고유 라인 데이터를 수집했다. 데이터 분석 결과, 라인 수정 확률은 시간에 따라 거의 일정한 지수 감소 형태를 보였으며, 파일 수정 확률은 보다 완만한 로그‑선형 패턴을 나타냈다.
이를 바탕으로 논문은 “단순 직관 모델”(Simple Intuitive Model, SIM)을 제안한다. SIM은 각 라인·파일이 다음 버전에서 수정될 확률을 (p_{line}=α·e^{-β·Δt}), (p_{file}=γ·\ln(1+Δt)) 형태로 표현한다(Δt는 버전 간 시간 차). 모델 파라미터 α, β, γ는 실제 관측값에 최소제곱법으로 피팅했으며, 세 프로젝트 모두 유사한 값(α≈0.03, β≈0.12, γ≈0.07)으로 수렴했다. 이는 다양한 코드베이스에서도 수정 행동이 공통적인 통계적 규칙을 따른다는 강력한 증거다.
모델을 적용해 “발견 가능성 구간”을 계산한다. 예를 들어, 5년(≈60개월) 동안 수정되지 않은 라인에 삽입된 제로데이는 라인‑레벨 발견 확률이 5 % 이하로 떨어진다. 반면 파일‑레벨 취약점은 동일 기간 동안 30 % 정도의 발견 확률을 유지한다. 즉, 은폐 수준에 따라 취약점이 살아남을 수 있는 시간 차이가 크게 벌어진다.
또한 논문은 공급망 공격 시나리오를 논의한다. 공격자는 악의적인 코드를 의도적으로 “덜 수정되는” 파일·라인에 삽입함으로써 발견 가능성을 최소화할 수 있다. 데이터에 따르면, 커널의 드라이버 디렉터리와 glibc의 내부 유틸리티 파일이 가장 낮은 수정 빈도를 보이며, 이러한 영역이 공급망 공격의 고위험 표적이 될 가능성이 높다.
마지막으로, 연구자는 모델의 한계도 명시한다. 실제 취약점 발견은 정적·동적 분석 도구, 자동화된 스캐너, 그리고 인간 리뷰어의 전문성에 크게 좌우되며, 라인·파일 수정 외에도 코드 복잡도, 의존성 그래프, 개발자 경험 등이 영향을 미친다. 그럼에도 불구하고, 본 모델은 “코드 베이스 내에서 취약점이 얼마나 오래 살아남을 수 있는가”를 추정하는 첫 번째 정량적 프레임워크로서 의미가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기