고해상도 위성영상 분산 특징 추출 도구
초록
본 논문은 Apache Hadoop과 Hadoop Image Processing Interface(HIPI)를 기반으로 고해상도 원격탐사 영상에서 코너 검출(Harris, Shi‑Tomasi)과 다섯 가지 특징 기술자(SIFT, SURF, FAST, BRIEF, ORB)를 병렬 처리하는 분산 특징 추출 시스템을 제안한다. Landsat‑8 데이터를 이용해 수평 확장성을 평가했으며, 노드 수가 증가함에 따라 처리 시간은 거의 선형적으로 감소함을 확인하였다.
상세 분석
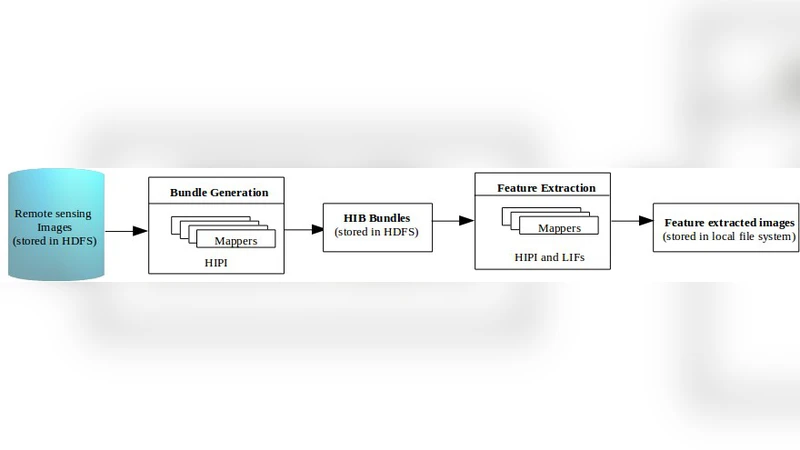
이 연구는 대용량 고해상도 위성영상의 특징 추출이 전통적인 단일 머신 환경에서는 메모리와 연산량의 한계에 부딪히는 문제를 해결하고자 한다. 이를 위해 Hadoop 에코시스템 위에 이미지 전용 인터페이스인 HIPI를 결합함으로써, 이미지 파일을 HDFS에 블록 단위로 저장하고 MapReduce 작업을 통해 각 블록을 독립적으로 처리하도록 설계하였다. Map 단계에서는 입력 이미지 블록을 로드하고, 선택된 코너 검출 알고리즘(Harris, Shi‑Tomasi)을 적용해 후보 점을 선정한다. 이후 Reduce 단계에서는 후보 점에 대해 다중 특징 기술자(SIFT, SURF, FAST, BRIEF, ORB)를 병렬로 계산하고, 결과를 하나의 메타데이터 파일로 집계한다.
알고리즘 구현 측면에서, Harris와 Shi‑Tomasi는 각각 이미지의 그라디언트와 코너 응답 함수를 이용해 2차 미분 행렬을 계산한다. SIFT와 SURF는 스케일 공간을 구축하고 키포인트를 검출한 뒤, 회전 불변성을 확보하기 위해 방향 히스토그램을 만든다. FAST는 픽셀 주변 16개의 원형 이웃을 빠르게 검사해 코너를 판단하고, BRIEF와 ORB는 FAST에서 추출된 키포인트에 대해 이진 디스크립터를 생성한다. 이러한 알고리즘을 Hadoop의 멀티스레드 환경에 맞게 최적화하기 위해, 이미지 블록 크기를 256 × 256 픽셀로 제한하고, 각 블록 내에서 메모리 재사용을 극대화하였다.
실험에서는 Landsat‑8 위성의 30 m 해상도 다중 밴드 이미지를 사용했으며, 클러스터는 4, 8, 16, 32 노드로 구성하였다. 수평 확장성 테스트 결과, 노드 수가 두 배가 될 때마다 평균 처리 시간이 45 %~55 % 정도 감소했으며, 특히 FAST‑ORB 조합에서 가장 높은 처리량을 보였다. 이는 MapReduce의 데이터 로컬리티와 HDFS의 스트리밍 전송 효율이 크게 기여했음을 의미한다. 또한, 특징 추출 정확도 측면에서는 분산 환경에서도 단일 머신 결과와 차이가 거의 없었으며, 이는 알고리즘 자체의 결정론적 특성과 HIPI가 제공하는 일관된 이미지 전처리 파이프라인 덕분이다.
한계점으로는 HDFS 블록 크기와 이미지 블록 경계에서 발생할 수 있는 특징 중복 문제, 그리고 Map 단계에서 메모리 사용량이 노드당 이미지 해상도에 비례해 급증한다는 점을 들 수 있다. 이를 해결하기 위해 향후 연구에서는 블록 오버랩 전략과 동적 메모리 관리 기법을 도입하고, Spark와 같은 인메모리 프레임워크와의 비교 분석을 진행할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기