소셜 미디어 사용자 특성 활용한 풍자 감지 향상
초록
본 논문은 Reddit의 대규모 SARC 데이터셋을 이용해 댓글 작성자의 특성을 두 가지 방식으로 모델링한다. 하나는 저자별 풍자 사용 빈도를 베이즈 사전으로 직접 활용하는 방법이고, 다른 하나는 저자마다 15차원 밀집 임베딩을 학습해 텍스트와의 복합 상호작용을 포착하는 방법이다. 실험 결과, 제한된 서브레딧에서는 베이즈 사전이 충분히 좋은 성능을 보였으며, 전체 데이터와 같이 다양성이 큰 경우에는 저자 임베딩이 최고 정확도를 달성한다.
상세 분석
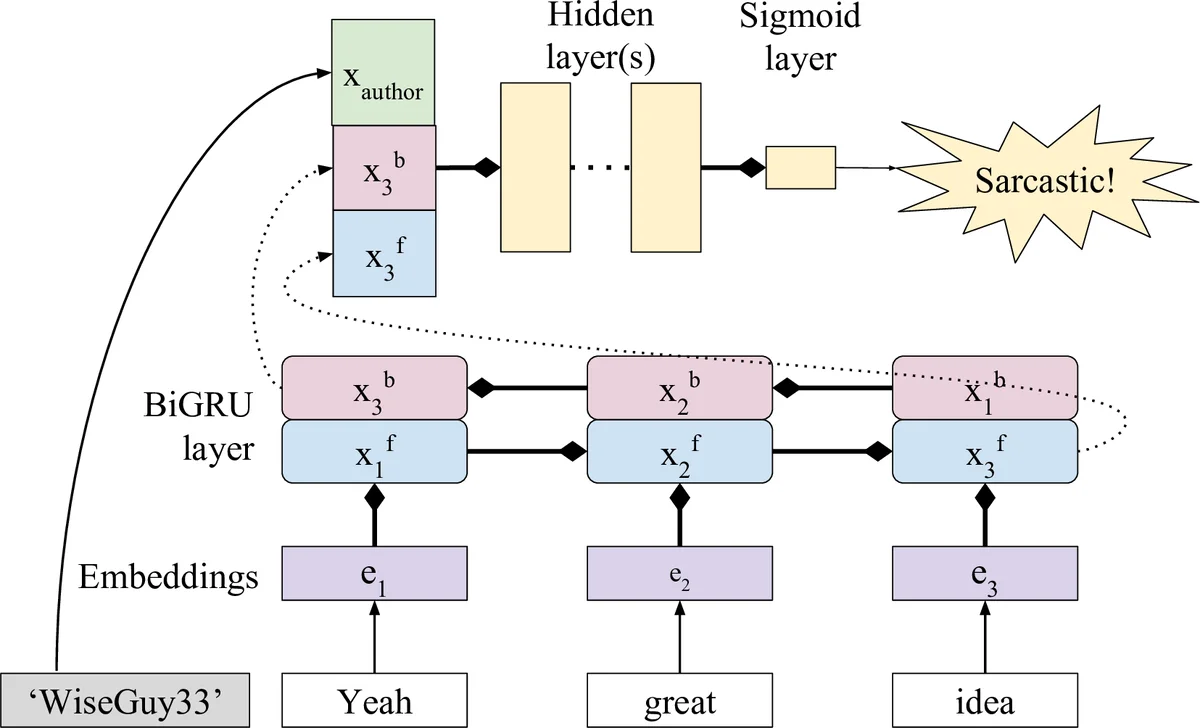
이 연구는 풍자 감지라는 고전적인 문맥 의존 문제에 ‘작성자’라는 메타 정보를 어떻게 효과적으로 통합할 수 있는지를 체계적으로 탐구한다. 기본 텍스트 인코더로 BiGRU(양방향 GRU)를 채택했으며, 이는 단어 수준 FastText 임베딩을 입력으로 받아 양방향 은닉 상태를 결합한다. 저자 모델링은 두 갈래로 나뉜다. 첫 번째는 베이즈 사전 방식으로, 훈련 데이터에서 각 저자가 남긴 풍자와 비풍자 댓글 수를 (s, n) 형태의 정수 벡터로 저장하고, 이를 베르누이 사전 확률로 변환해 텍스트 인코더와 결합한다. 새로운 저자에 대해서는 (0, 0)으로 초기화해 균등 사전으로 처리한다. 두 번째는 저자 임베딩 방식으로, 각 저자를 15차원 실수 벡터로 초기화하고 학습 과정에서 동시에 업데이트한다. 훈련 시 미지의 저자에 대해서는 별도의 UNK 임베딩을 사용한다. 두 방법 모두 텍스트와 저자 정보를 결합한 후 하나 또는 두 개의 전결합 레이어와 ReLU를 거쳐 시그모이드 출력층에 연결한다.
실험은 전체 SARC(균형 샘플)와 r/politics, r/AskReddit 서브레딧의 균형·불균형 버전을 포함한 다섯 데이터셋에서 수행되었다. 평가 지표는 매크로 평균 F1이며, 각 실험을 10번 반복해 부트스트랩 95% 신뢰구간을 제시한다. 결과는 다음과 같다. 소규모·주제 집중 서브레딧에서는 베이즈 사전이 가장 높은 F1를 기록했으며, 이는 저자별 풍자 빈도가 충분히 안정적이기 때문이다. 반면 전체 데이터셋에서는 저자 임베딩이 베이즈 사전보다 평균 0.5~1.0%p 정도 높은 점수를 얻어, 풍자와 비풍자 사이의 복합적 상호작용을 학습할 수 있음을 보여준다. 또한, 베이스라인인 ‘No embed’ 모델보다 두 저자 모델이 모두 유의미하게 개선된 점은 저자 정보 자체가 강력한 신호임을 입증한다.
정성적 분석에서는 베이즈 사전이 특정 저자의 풍자 사용 빈도만을 반영해 오탐을 줄이는 경우가, 저자 임베딩은 저자 고유의 언어 습관(예: 특정 어휘·구문 사용)까지 포착해 정답률을 높이는 경우가 관찰되었다. 그러나 임베딩 모델은 훈련 데이터가 부족한 저자에 대해 과도하게 높은 풍자 확률을 부여해 오히려 성능을 저하시킬 수 있음을 사례를 통해 지적한다. 이는 모델 복잡도와 데이터 양 사이의 트레이드오프를 시사한다.
전체적으로 이 논문은 (1) 저자 특성을 단순 베이즈 사전으로도 충분히 활용 가능함을, (2) 데이터 규모와 다양성이 커질수록 고차원 임베딩이 더 큰 이점을 제공함을, (3) 저자별 데이터 양에 따라 동적으로 모델 복잡도를 조절하는 하이브리드 접근법이 향후 연구에 유망함을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기