심층 학습 기반 스택드 오토인코더로 극비만 유전체 분석
초록
본 연구는 GWAS의 선형 한계를 극복하고 SNP 간 상호작용을 탐지하기 위해 스택드 오토인코더(SAE)를 활용한 딥러닝 파이프라인을 제시한다. p‑값 0.01 이하인 2,000여 개 SNP를 입력으로 하여 다층 은닉층을 순차적으로 압축하고, 최종적으로 다층 퍼셉트론 분류기를 미세조정한다. 압축 차원 2,000일 때 AUC 0.975, 민감도 0.949, 특이도 0.933을 달성했으며, 차원을 50으로 줄여도 AUC 0.852 수준을 유지한다.
상세 분석
이 논문은 비만이라는 다인자 형질을 해석하기 위해 기존 GWAS가 제공하는 선형 연관성 분석을 넘어, 비선형 및 상호작용 효과를 포착할 수 있는 딥러닝 접근법을 적용하였다. 먼저, 연구자는 대규모 코호트에서 얻은 전장 유전체 데이터와 BMI 정보를 이용해 SNP‑BMI 연관 검정을 수행했으며, 보수적인 보정 없이 p‑값 1×10⁻² 미만인 변이를 선택하였다. 이는 Bonferroni 보정이 과도하게 엄격해 실제 의미 있는 약한 효과를 가진 변이를 배제하는 문제를 회피하기 위한 전략이다. 선택된 SNP는 약 2,000여 개에 불과했지만, 이들 사이에 존재할 수 있는 복잡한 에피스타시스(epistasis)를 탐색하기에 충분한 규모였다.
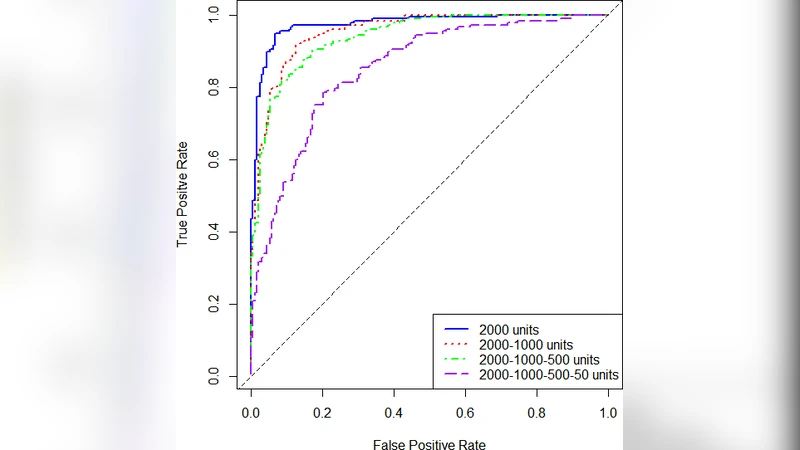
스택드 오토인코더(SAE)는 다층 비지도 학습 구조로, 각 레이어가 이전 레이어의 출력(압축된 표현)을 입력으로 받아 점진적으로 차원을 축소한다. 논문에서는 초기 레이어에 2,000개의 은닉 유닛을 두고, 이후 1,000, 500, 200, 50 등 점진적으로 감소시키는 계층 구조를 실험하였다. 각 레이어는 ReLU 활성화와 평균 제곱 오차(MSE) 손실 함수를 사용해 학습되었으며, 가중치는 사전 학습된 오토인코더 가중치로 초기화되어 전이 학습 효과를 극대화했다.
압축된 특징 벡터는 이후 다층 퍼셉트론(MLP) 분류기에 전달되었으며, 이 단계에서 지도 학습이 수행된다. 분류기의 최종 출력은 극비만(예: BMI ≥ 40)과 비비만(예: BMI < 30) 두 클래스로 구분한다. 학습 과정에서는 교차 엔트로피 손실과 Adam 옵티마이저를 사용했으며, 과적합 방지를 위해 드롭아웃과 L2 정규화를 적용하였다. 모델 평가는 민감도(SE), 특이도(SP), Gini 계수, 로그 손실, AUC, MSE 등 다양한 지표로 수행되었다.
실험 결과, 2,000개의 압축 유닛을 사용한 경우 AUC 0.97497, SE 0.949153, SP 0.933014, Gini 0.949936, 로그 손실 0.1956, MSE 0.054057을 기록하였다. 차원을 50으로 축소했을 때에도 AUC 0.85178, SE 0.785311, SP 0.799043 등 비교적 높은 성능을 유지하였다. 이는 SAE가 고차원 SNP 데이터에서 핵심적인 비선형 상호작용을 효과적으로 추출하고, 차원 축소에도 강인한 분류 능력을 보존한다는 것을 의미한다.
하지만 몇 가지 한계점도 존재한다. 첫째, p‑값 임계값을 0.01로 설정함으로써 실제 의미 없는 잡음 변이가 포함될 가능성이 있다. 둘째, 모델은 특정 코호트에 대해 학습되었으므로 다른 인구 집단에 대한 일반화 능력을 검증하기 위한 외부 검증이 부족하다. 셋째, 오토인코더 구조와 하이퍼파라미터 선택이 경험적이며, 자동화된 최적화 절차가 부재하다. 향후 연구에서는 베이즈 최적화나 강화학습을 통한 하이퍼파라미터 탐색, 다인종 데이터셋을 활용한 교차 검증, 그리고 SNP‑SNP 상호작용을 직접 해석할 수 있는 가시화 기법을 도입함으로써 모델의 신뢰성과 해석 가능성을 높일 수 있을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기