BLEU 점수의 미분 가능한 하한을 이용한 효율적 직접 최적화
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
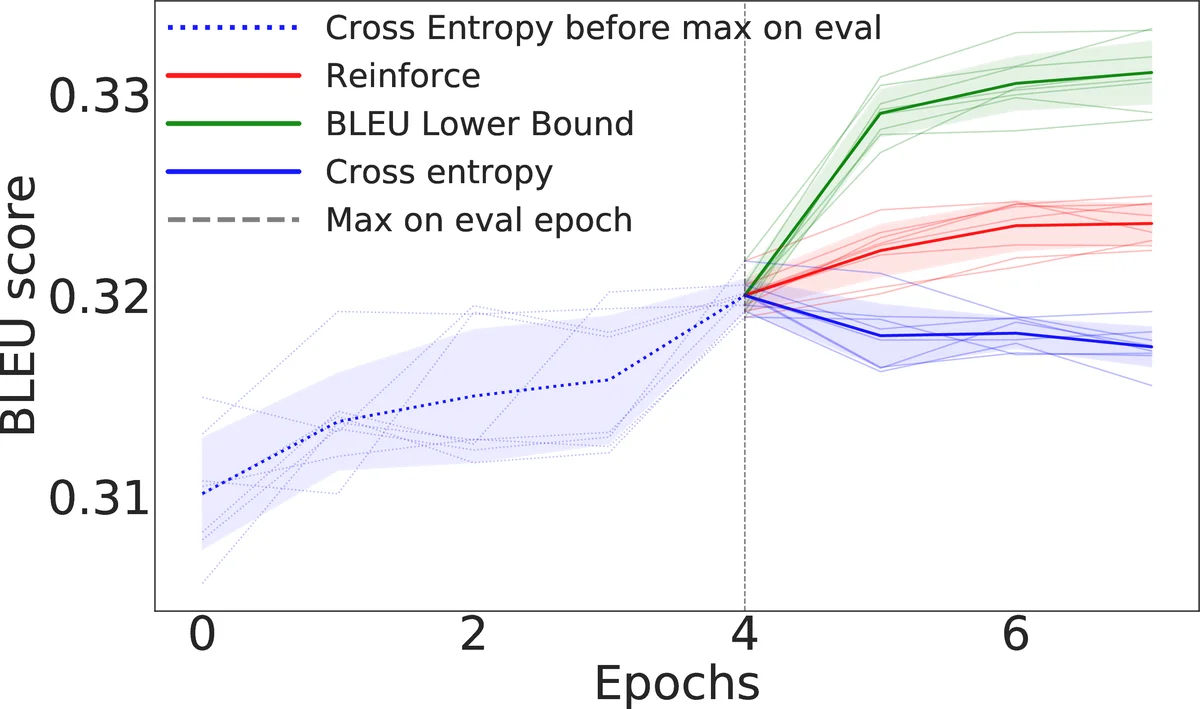
본 논문은 기계 번역 등 NLP 과제에서 널리 쓰이는 비미분 가능 지표인 BLEU 점수의 기대값에 대한 미분 가능한 하한(Lower Bound, LB)을 제안한다. 기존 REINFORCE 기반 강화학습 방식은 샘플링에 의한 고분산 문제와 계산 비용이 크다는 단점을 가지고 있었는데, 저자는 BLEU 점수를 행렬 형태로 재표현하고 Jensen 부등식 등을 활용해 기대 BLEU의 하한을 닫힌 형태로 도출한다. 이 하한은 확률 분포 파라미터에 대해 완전 자동 미분이 가능하므로, 샘플링 없이도 직접적인 목표 지표 최적화가 가능하다. 실험에서는 toy task와 두 규모의 독일‑영어 번역 데이터셋(IWSLT‑14, WMT‑14)에서 제안 방법이 교차 엔트로피와 REINFORCE 기반 최적화보다 높은 BLEU 점수를 달성함을 보였다.
상세 분석
이 논문은 BLEU 점수의 비미분 가능성을 극복하기 위해 두 단계 접근법을 제시한다. 첫 번째는 후보 문장 C와 기준 문장 R을 각각 원-핫 행렬 x, y 로 표현하고, n‑gram 매칭을 나타내는 행렬 Sₙ, Pₙ 을 정의함으로써 BLEU의 정밀도 pₙ 를 완전한 행렬 연산으로 재구성한다. 이렇게 하면 Count 연산이 사라지고, 모든 연산이 연속적이면서 미분 가능해진다. 두 번째 단계에서는 기대 BLEU, 즉 Eₓ∼pₓ
댓글 및 학술 토론
Loading comments...
의견 남기기