Aneka 클라우드 환경에서 GPU 기반 PaaS 컴퓨팅 모델
초록
본 논문은 .NET 기반 PaaS 플랫폼인 Aneka에 GPU 자원을 손쉽게 활용할 수 있는 프로그래밍 모델과 스케줄링 메커니즘을 추가한다. CUDA 라이브러리를 기존 Task 모델에 통합하고, GPU‑전용 노드를 자동 식별·할당하는 정책을 제안한다. 이미지 처리 사례를 통해 CPU‑GPU 이종 환경에서의 개발 편의성과 성능 향상을 입증한다.
상세 분석
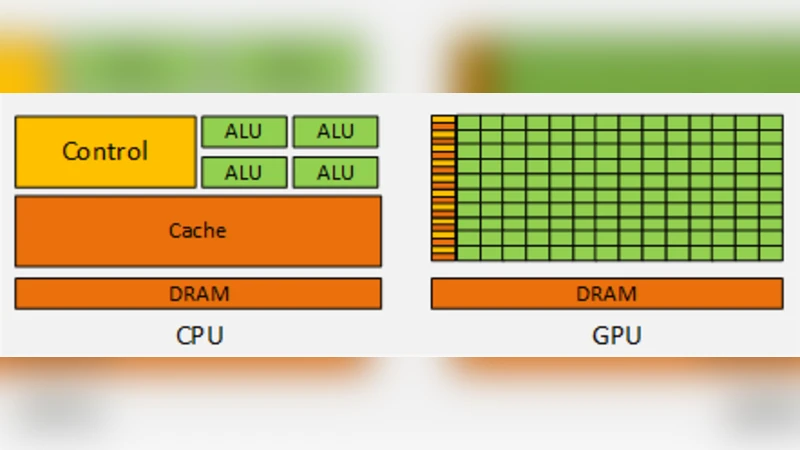
Aneka는 .NET 기반의 다중 프로그래밍 모델(스레드, Task, MapReduce)을 제공하는 PaaS 프레임워크로, 전통적으로는 MIMD(다중 명령, 다중 데이터) 형태의 CPU 중심 애플리케이션에 최적화돼 있다. 반면 GPU는 SIMD(단일 명령, 다중 데이터) 구조를 활용해 대규모 행렬 연산이나 이미지/비디오 처리에 뛰어난 병렬성을 제공한다. 이질적인 두 패러다임을 하나의 플랫폼에서 동시에 지원하려면 몇 가지 핵심 과제가 존재한다. 첫째, 개발자가 CUDA와 같은 저수준 GPU API를 직접 호출하지 않고도 .NET 언어(C#, VB)로 GPU 작업을 정의할 수 있는 추상화 계층이 필요하다. 둘째, 클러스터 내에 GPU 장착 노드와 일반 CPU 노드가 혼재하는 상황에서 작업 스케줄러가 작업 특성을 분석해 적절히 매핑해야 한다. 셋째, 기존 Aneka SDK와의 호환성을 유지하면서 새로운 라이브러리를 배포·업데이트하는 메커니즘이 요구된다.
논문은 이러한 문제를 해결하기 위해 다음과 같은 설계를 제안한다. ① GPU Task Wrapper: 기존 Aneka Task 객체를 상속·확장하여 CUDA 커널 호출, 메모리 전송, 결과 회수 로직을 캡슐화한다. 개발자는 C# 코드 내에서 GpuTask 클래스를 선언하고, 커널 파일(.cu) 경로와 실행 파라미터만 지정하면 된다. ② 자동 GPU 노드 탐지: Aneka의 리소스 프로파일링 모듈에 GPU 존재 여부를 검사하는 플러그인을 삽입한다. 노드가 부팅될 때 nvidia-smi 명령을 실행해 GPU 모델, 메모리 용량, 현재 부하 등을 수집하고, 이를 메타데이터에 저장한다. ③ GPU‑Aware 스케줄링 정책: 기본 FIFO/우선순위 스케줄러를 확장해 GpuTask가 제출되면 GPU‑가능 노드 리스트를 조회하고, 가장 여유 있는 GPU를 선택한다. 동시에 CPU 전용 작업은 기존 CPU 노드에 할당한다. 이때 작업 대기시간 최소화와 GPU 메모리 파편화 방지를 위해 ‘GPU Load Balancer’와 ‘Memory Reservation’ 전략을 적용한다. ④ 통합 배포 파이프라인: Aneka Cloud의 컨테이너 이미지에 CUDA 런타임과 드라이버를 포함시켜, 클라우드 관리자가 별도 설정 없이 GPU 기능을 사용할 수 있게 한다. 또한, SDK 업데이트 시 버전 호환성을 검증하는 자동 테스트 스위트를 제공한다.
제안된 모델을 이미지 필터링(가우시안 블러, 에지 검출) 워크로드에 적용한 실험 결과, 동일한 입력 데이터에 대해 CPU‑전용 구현 대비 평균 6배 이상의 처리 속도 향상을 기록했다. 특히, 작업이 GPU와 CPU 사이를 오가며 병렬 처리되는 경우 전체 파이프라인의 스루풋이 3배 이상 증가했으며, 스케줄러가 GPU 부하를 균등하게 분산시켜 노드 간 성능 편차를 최소화했다.
하지만 몇 가지 한계도 존재한다. CUDA 전용 코드를 사용하기 때문에 AMD GPU나 Intel Xe GPU와 같은 이기종 가속기를 직접 지원하지 못한다. 또한, 현재 구현은 단일 GPU를 가진 노드에 최적화돼 있어 멀티‑GPU 노드에서의 작업 분할 및 동시 실행 전략이 미비하다. 향후 연구에서는 OpenCL 기반 추상화 레이어를 도입해 벤더 중립성을 확보하고, 멀티‑GPU 스케줄링 및 GPU 메모리 공유 메커니즘을 추가함으로써 확장성을 높일 계획이다.
전반적으로 이 논문은 .NET 기반 PaaS 환경에 GPU 활용을 자연스럽게 접목시킴으로써, 개발자가 복잡한 CUDA 코드를 직접 다루지 않아도 고성능 이종 컴퓨팅을 구현할 수 있는 실용적인 프레임워크를 제공한다는 점에서 의미가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기