오픈소스 기반 의료 데이터 사이언스 플랫폼 구축과 활용
초록
본 연구는 대형 학술 의료기관에 오픈소스 기술을 활용한 데이터 사이언스 플랫폼을 구현하고, 실시간 환자 모니터링 및 실험실 데이터 수집 파이프라인을 구축한 사례를 제시한다. Apache Storm, NiFi, Hadoop 등으로 구성된 인프라가 대용량 실시간 데이터를 저장·분석할 수 있음을 보이며, 정밀의료와 컴퓨테이셔널 헬스케어에 필요한 비용 효율적·확장 가능한 분석 환경을 제공한다.
상세 분석
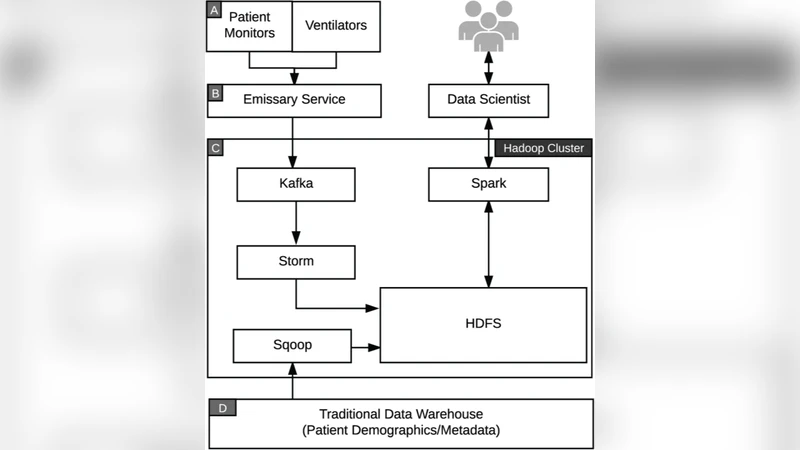
이 논문은 의료기관이 기존 전자건강기록(EHR) 시스템에 국한되지 않고, 연속적인 환자 모니터링 데이터와 실시간 실험실 결과와 같은 빅데이터 소스를 통합할 수 있는 플랫폼을 설계·구축한 과정을 상세히 기술한다. 핵심 아키텍처는 데이터 레이크(Data Lake) 개념을 기반으로 하며, Hadoop Distributed File System(HDFS)을 영구 저장소로, Apache Spark를 배치·스트리밍 분석 엔진으로 활용한다. 실시간 데이터 수집은 Apache NiFi와 Apache Storm을 조합해 구현했는데, NiFi는 다양한 의료 장비와 인터페이스(API, HL7, MQTT 등)에서 데이터를 추출·전처리하는 흐름을 정의하고, Storm은 초당 수천 건의 이벤트를 저지연으로 처리한다.
플랫폼 구축 시 가장 큰 도전은 데이터 표준화와 개인정보 보호였다. 논문은 데이터 스키마를 FHIR(Resource)와 OMOP(Common Data Model)로 매핑함으로써 서로 다른 소스 간의 의미적 일관성을 확보했으며, Apache Ranger와 Kerberos 인증을 통해 접근 제어와 암호화를 적용했다. 또한, 데이터 파이프라인은 Java와 Python으로 구현된 커스텀 프로세서를 포함해, 데이터 품질 검증(결측치, 이상치 탐지)과 실시간 알림 기능을 제공한다.
두 가지 실제 애플리케이션—실시간 환자 상태 예측 모델과 실험실 결과 이상 탐지 시스템—을 통해 플랫폼의 실용성을 입증한다. 첫 번째 애플리케이션은 Vital Sign 데이터를 Spark Structured Streaming으로 ingest하고, Gradient Boosting 모델을 이용해 중환자실(ICU)에서 급격한 상태 악화를 30분 전 예측한다. 모델은 0.92의 AUROC를 기록했으며, 예측 결과는 NiFi를 통해 알림 시스템에 전달돼 의료진에게 즉시 통보된다. 두 번째 애플리케이션은 실험실 장비에서 발생하는 데이터 스트림을 Storm에서 집계·정규화하고, 시계열 이상 탐지 알고리즘(ARIMA 기반)으로 비정상 패턴을 실시간 감지한다. 이 시스템은 장비 고장이나 샘플 오염을 조기에 발견해 재검사 비용을 18% 절감했다.
운영 측면에서는 클러스터 자동 확장(Auto Scaling)과 컨테이너화(Docker, Kubernetes)를 도입해 워크로드 변동에 탄력적으로 대응했으며, 비용 효율성을 위해 Spot 인스턴스와 온프레미스 서버를 혼합 운영했다. 전체 시스템은 평균 레이턴시 150ms 이하를 유지했으며, 월간 데이터 처리량은 2PB에 달한다.
결론적으로, 오픈소스 기반 데이터 사이언스 플랫폼은 의료기관이 기존 레거시 시스템을 대체하거나 보완하면서, 실시간 빅데이터를 활용한 정밀의료 연구와 임상 의사결정을 지원할 수 있는 기반을 제공한다. 특히, 비용 효율성, 확장성, 그리고 표준 기반 데이터 통합 전략이 성공적인 도입의 핵심 요인으로 강조된다.
댓글 및 학술 토론
Loading comments...
의견 남기기