데이터텍스트 기술로 의료 데이터 활용 극대화
초록
본 논문은 데이터‑텍스트(NLG) 기술을 의료 현장에 적용하는 방법을 체계적으로 정리한다. 데이터‑텍스트 파이프라인, 주요 의료 도메인(재무 보고, 임상 요약, 환자 커뮤니케이션)에서의 활용 사례, 그리고 구현·평가 시 고려해야 할 연구 과제들을 제시한다.
상세 분석
논문은 데이터‑텍스트 기술을 “무엇을 알고 있는가(What is known) → 무엇을 말할 수 있는가(What can be said) → 무엇을 말할 것인가(What to say) → 어떻게 말할 것인가(How to say) → 실제 발화(Actually saying it)”의 5단계 파이프라인으로 구조화한다. ‘What is known’ 단계에서는 SNOMED‑CT·OBO 등 의료 온톨로지를 활용해 도메인 지식을 표준화하고, 데이터베이스와 연결한다. ‘What can be said’ 단계는 시계열 신호 처리, 통계 분석, 위험도 추정 등 데이터 해석 알고리즘을 적용해 의미 있는 이벤트를 추출한다. ‘What to say’에서는 콘텐츠 선정과 텍스트 구조화를 담당하며, 특히 Rhetorical Structure Theory(RST)를 이용해 인과·시간·대조 관계를 그래프로 모델링한다. ‘How to say’ 단계는 문장 집합화, 어휘 선택, 지시 표현 생성 등을 포함해 가독성과 일관성을 높인다. 마지막 ‘Actually saying it’는 문법적으로 정확한 문장을 생성하는 실현 엔진이다.
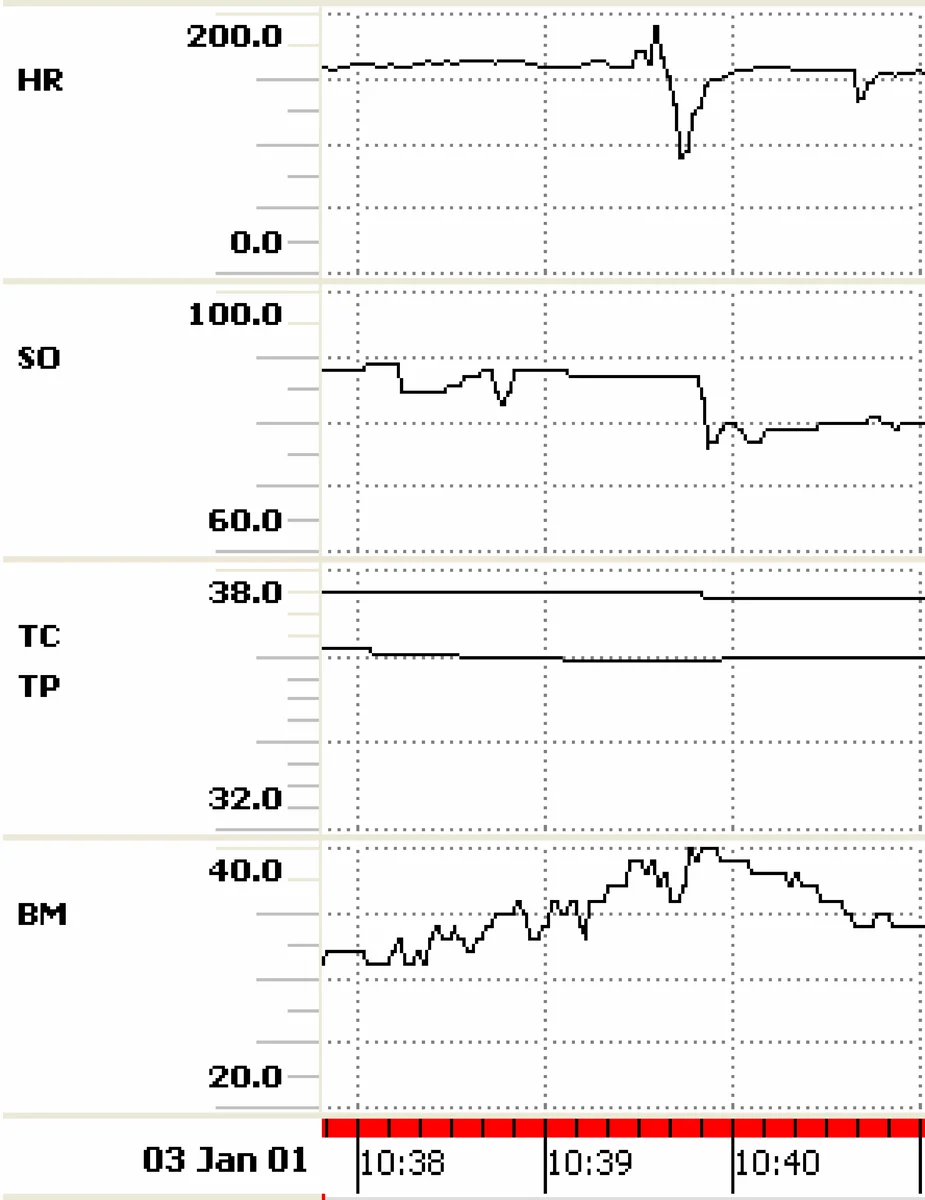
핵심 사례로 제시된 Babytalk BT‑45 시스템은 신생아 중환자실의 45분 데이터를 요약해 의사결정을 지원한다. 입력 시계열(심박, 산소포화도, 혈압 등)을 온톨로지 기반 규칙과 결합해 ‘서맥·산소 저하·혈압 상승·모르핀 투여’와 같은 이벤트를 식별하고, 중요도 점수를 매겨 콘텐츠를 선정한다. 이후 RST 그래프를 구성해 모르핀 투여가 다른 이벤트의 원인일 가능성을 반영, 관련 이벤트를 같은 문장에 집계한다. 최종 텍스트는 “10시 39분에 모르핀을 투여하였다. 순간적인 서맥이 발생했고 평균 혈압이 40으로 상승하였다. 산소 포화도는 79로 감소하였다.”와 같이 23단어로 압축된다.
논문은 데이터‑텍스트가 의료 전문가의 문서작성 부담을 크게 경감하고, 일관성·신속성을 확보함으로써 환자 안전과 비용 효율성을 높일 수 있음을 강조한다. 그러나 데이터 품질, 온톨로지 유지보수, 임상 검증, 사용자 맞춤형 스타일링 등 실용화에 남은 과제도 다룬다. 특히, 의료 규제와 개인정보 보호 요구사항을 만족시키면서도 실시간 생성 성능을 확보하는 것이 주요 연구 과제로 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기