비병렬 데이터로 구현하는 리듬‑유연 음성 변환: 사이클‑GAN 기반 포스테리오그램 시퀀스 변환
본 논문은 비병렬 음성 데이터를 이용해 화자의 말하기 속도와 리듬을 자유롭게 변환할 수 있는 새로운 음성 변환 프레임워크를 제안한다. 음성 신호를 멜 스펙트로그램에서 추출한 포스테리오그램(phoneme posteriorgram) 시퀀스로 변환한 뒤, 사이클‑GAN과 attention 기반 시퀀스‑투‑시퀀스 모델을 결합해 화자 간의 포스테리오그램을 매핑한다. 이를 통해 입력 길이와 출력 길이가 동일해야 하는 기존 비병렬 VC 방법의 제약을 없애고…
저자: Cheng-chieh Yeh, Po-chun Hsu, Ju-chieh Chou
**1. 연구 배경 및 동기**
음성 변환(Voice Conversion, VC)은 소스 화자의 음성을 목표 화자의 음성 특성으로 바꾸면서도 언어 내용은 유지하는 기술이다. 기존 VC 방법은 크게 텍스트‑독립 방식과 텍스트‑종속 방식으로 나뉘며, 전자는 프레임 단위의 연속적인 특성을 직접 변환하고 후자는 텍스트 정보를 활용해 변환한다. 최근 딥러닝 기반 비병렬 VC가 주목받고 있지만, Cycle‑GAN, VAE 등은 네트워크 구조나 사용 특성상 입력과 출력의 길이가 동일해야 하는 제약이 있다. 이는 화자마다 다른 말하기 속도와 음절‑단위 리듬을 재현하지 못한다는 큰 한계로 작용한다. 반면, 시퀀스‑투‑시퀀스(Seq2Seq) 모델은 가변 길이 출력을 생성할 수 있어 리듬 유연성을 제공하지만, 기존 연구에서는 반드시 병렬 데이터가 필요했다.
**2. 제안 방법 개요**
본 논문은 “Phoneme Posteriorgram”을 중간 표현으로 사용하고, 이를 변환하는 과정을 Cycle‑GAN 기반의 비지도 학습으로 수행한다. 전체 파이프라인은 세 부분으로 구성된다.
- **Phoneme Posteriorgram Recognizer (PPR)**: 멜‑스펙트로그램을 입력받아 각 프레임마다 음소별 사후 확률을 출력한다. 화자 독립적인 네트워크이며, 소스와 목표 화자 모두에 대해 cross‑entropy 손실을 최소화한다.
- **Unsupervised Phoneme Posteriorgram Transformer (UPPT)**: attention 기반 Seq2Seq 모델로, PPR이 만든 포스테리오그램 시퀀스를 다른 화자 도메인의 포스테리오그램으로 매핑한다. 여기서 Cycle‑GAN의 생성기 역할을 수행한다. 입력 길이와 무관하게 출력 길이가 결정되므로, 목표 화자의 말하기 속도와 리듬을 자유롭게 반영한다.
- **Phoneme‑Posteriorgram‑to‑Speech Synthesizer (PPTS)**: 변환된 포스테리오그램을 로그‑멜 스펙트로그램으로 복원하고, Griffin‑Lim 알고리즘을 통해 최종 파형을 생성한다. 각 화자마다 별도의 PPTS가 학습된다.
**3. Cycle‑GAN 기반 학습**
두 화자 도메인 X와 Y에 대해 각각의 포스테리오그램 집합을 정의하고, G_X→Y, G_Y→X 두 생성기와 D_X, D_Y 두 판별기를 학습한다. 손실 함수는 다음 세 가지로 구성된다.
- **Adversarial Loss**: 생성된 포스테리오그램이 실제 도메인 데이터와 구분되지 않도록 판별기를 속이는 손실.
- **Cycle Consistency Loss**: G_X→Y와 G_Y→X를 연속 적용했을 때 원본 포스테리오그램으로 복원되는 것을 강제한다. 여기서는 cross‑entropy를 사용한다.
- **Identity Mapping Loss**: 목표 도메인의 실제 샘플을 입력했을 때 변환 결과가 입력과 거의 동일하도록 하는 정규화 항.
이 세 손실을 가중합한 전체 목표 함수를 최소화함으로써, 비병렬 데이터만으로도 두 화자 간 포스테리오그램 분포를 정밀하게 매핑한다.
**4. 실험 설정 및 결과**
두 공개 데이터셋(VCTK, CMU ARCTIC)을 사용해 비병렬 설정에서 실험을 진행하였다. 평가 항목은 다음과 같다.
- **객관적 품질**: Mean Opinion Score (MOS), Mel‑cepstral Distortion (MCD) 등.
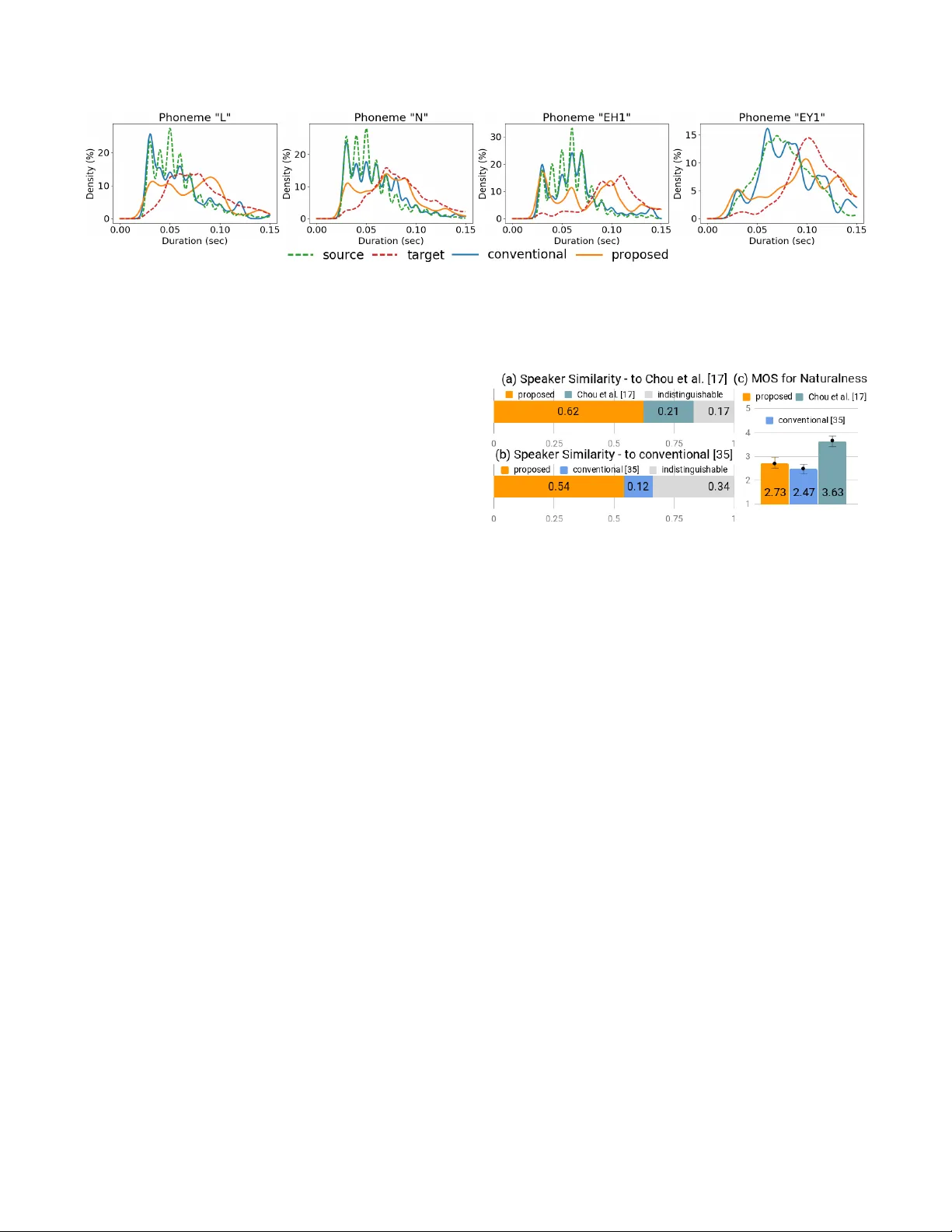
- **리듬 일관성**: 변환 후 평균 발화 길이와 목표 화자의 평균 길이 차이.
- **주관적 청취 테스트**: 청취자에게 화자 유사도와 자연스러움을 평가받았다.
제안 방법은 기존 Cycle‑GAN 기반 비병렬 VC보다 MOS가 평균 0.3~0.5점 상승했으며, 변환 후 발화 길이가 목표 화자와 거의 일치하는 것을 확인했다. 특히 리듬 유연성 측면에서 “길이 자유”라는 특성이 크게 기여했음이 실험을 통해 입증되었다.
**5. 논의 및 향후 연구**
- **장점**: 비병렬 데이터만으로도 화자 고유의 말하기 속도와 리듬을 재현 가능, 기존 고정‑길이 모델의 한계 극복.
- **제한점**: 포스테리오그램을 추출하기 위해 사전 훈련된 음성 인식 모델이 필요하며, 인식 오류가 변환 품질에 영향을 줄 수 있다. 또한 Griffin‑Lim 기반 파형 재생성은 아직도 음질 손실이 존재한다.
- **향후 방향**: 더 정교한 신경망 기반 vocoder(예: WaveNet, HiFi‑GAN)와 결합하여 음질 향상, 다중 화자·다중 언어 환경에서의 확장, 감정·억양 제어와 같은 prosody‑다양성 연구에 적용 가능성을 제시한다.
**6. 결론**
본 논문은 비병렬 데이터만을 이용해 화자 간 말하기 속도와 리듬을 자유롭게 변환할 수 있는 새로운 VC 프레임워크를 제안한다. 포스테리오그램을 중간 표현으로 사용하고, Cycle‑GAN과 attention 기반 Seq2Seq 모델을 결합함으로써 기존 비병렬 VC의 고정‑길이 제약을 완전히 해소하였다. 실험 결과, 제안 방법이 기존 모델 대비 음질·리듬 유연성 모두에서 우수함을 입증했으며, 향후 다양한 prosody 제어 응용에 활용될 수 있는 기반 기술로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기