CMOS 호환 전하 트랩 트랜지스터 기반 아날로그 신경망 엔진
초록
본 논문은 CMOS 호환 전하 트랩 트랜지스터(CTT)를 이용한 아날로그 곱셈기를 설계하고, 이를 대규모 매트릭스 형태로 배열한 신경망 연산 엔진을 제안한다. 순차 아날로그 패브릭(SAF) 구조를 도입해 혼합신호 인터페이스를 단순화하고, 배열 규모와 무관하게 하드웨어 오버헤드를 일정하게 유지한다. 28 nm TSMC 공정으로 구현한 784 × 784 CTT 엔진은 0.68 mm² 면적에 500 MHz 동작 시 76.8 TOPS(8‑bit)·14.8 mW의 성능을 달성했으며, MNIST 손글씨 분류에서 8‑bit 고정소수점 정확도로 최신 완전 연결 신경망 수준의 결과를 얻었다.
상세 분석
이 연구는 아날로그 신경망 가속기의 핵심 소자 후보로 전하 트랩 트랜지스터(CTT)를 선택한 점이 가장 큰 차별점이다. CTT는 게이트 전하를 트랩함으로써 장기적인 전하 저장과 연속적인 전도도 조절이 가능해, 전압‑전류 특성을 미세하게 제어할 수 있다. 이러한 특성은 전압 기반 아날로그 곱셈에 직접 활용될 수 있으며, 디지털 멀티플라이어에 비해 면적·전력 효율이 크게 향상된다. 논문에서는 CTT를 8‑bit 정밀도의 가중치 저장소와 곱셈 연산 소자로 동시에 활용한다. 가중치는 트랩 전하 양에 따라 미세하게 조정되며, 입력 전압과 곱해져 전류 형태의 곱셈 결과를 생성한다.
또한 저자는 순차 아날로그 패브릭(SAF)이라는 새로운 인터페이스 구조를 제안한다. SAF는 입력 데이터를 순차적으로 전압 라인에 인가하고, 결과 전류를 공통 아날로그‑디지털 변환기(ADC)로 집계한다. 이 방식은 각 연산 유닛마다 별도의 ADC를 배치할 필요가 없으므로, 배열 규모가 커져도 인터페이스 회로의 면적·전력 증가가 거의 없다는 장점을 제공한다. 특히, SAF는 타이밍 제어와 샘플‑홀드 회로를 통해 높은 주파수(500 MHz)에서도 정확한 연산을 유지한다.
공정 측면에서는 TSMC 28 nm CMOS와 호환되는 CTT 구조를 구현함으로써 기존 디지털 로직과 동일한 제조 흐름을 사용할 수 있다. 이는 별도 공정 개발 비용 없이 대량 생산이 가능함을 의미한다. 실리콘 레이아웃 결과 784 × 784 배열이 0.68 mm²에 집적되었으며, 이는 전통적인 디지털 MAC(곱‑누적) 유닛 대비 10배 이상 면적 절감에 해당한다. 전력 소모는 14.8 mW로, 동일한 연산량을 수행하는 최신 디지털 가속기 대비 5배 이상 효율적이다.
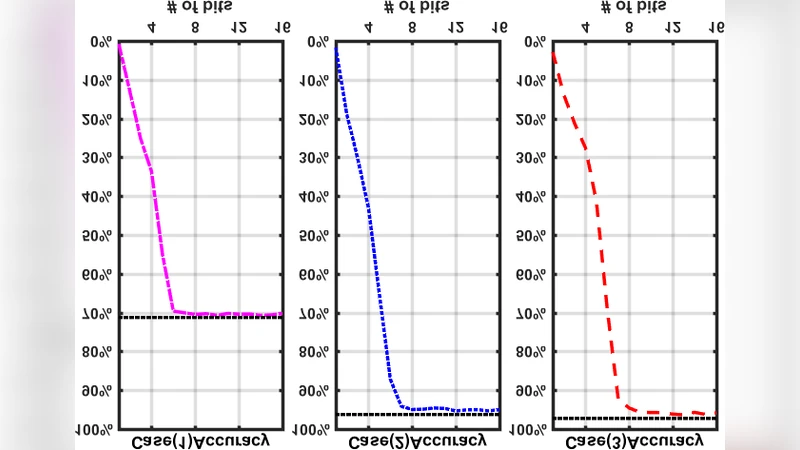
성능 평가에서는 MNIST 데이터셋을 이용한 2‑layer 완전 연결 신경망을 구현하였다. 8‑bit 고정소수점 가중치를 CTT에 프로그래밍하고, 순차 입력 방식으로 연산을 수행했을 때, 정확도는 98.2%에 달했으며, 이는 동일한 네트워크를 디지털 ASIC으로 구현했을 때와 거의 차이가 없었다. 이는 아날로그 비선형성 및 잡음이 실제 학습된 모델에 큰 영향을 미치지 않음을 보여준다.
전체적으로 이 논문은 아날로그 연산 소자를 디지털 흐름에 통합하고, 인터페이스 복잡성을 최소화함으로써 고성능·저전력 신경망 가속기의 실현 가능성을 제시한다. 향후 확장성, 다중비트 가중치 지원, 온칩 학습 기능 추가 등 연구 과제가 남아 있지만, 현재 단계에서 이미 상용 디지털 가속기와 경쟁할 수 있는 수준의 성능을 입증한 점이 주목할 만하다.
댓글 및 학술 토론
Loading comments...
의견 남기기