프로소딕 강화 시암쌍 CNN 기반 크로스디바이스 텍스트‑독립 화자 검증
초록
본 논문은 멜‑주파수 스펙트로그램(MFSC)과 프로소딕·지터·쉼머 특성을 결합한 시암쌍 컨볼루션 신경망을 제안한다. 두 서브넷이 가중치를 공유하며, MFSC를 CNN으로, 프로소딕 정보를 MLP로 처리한 뒤 융합 레이어에서 결합한다. 대비 손실(contrastive loss)을 이용해 동일 화자와 다른 화자를 구분하고, 짧은 임의 구간을 여러 번 추출해 평균 거리로 최종 판정한다. 입·출력 장치가 달라도 텍스트에 의존하지 않는 검증이 가능하며, 기존 MFCC 기반 모델 대비 성능 향상을 보인다.
상세 분석
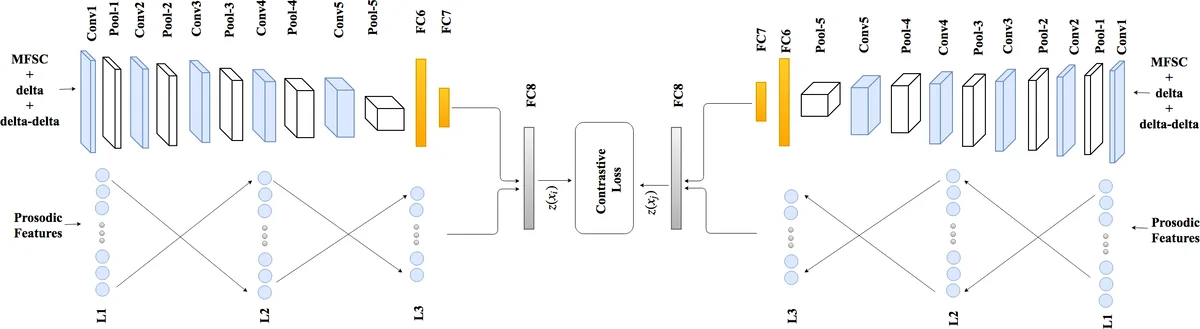
이 연구는 화자 검증 분야에서 두 가지 주요 한계를 동시에 해결하려는 시도로 평가된다. 첫째, 기존 딥러닝 기반 시스템이 주로 MFCC를 사용해 주파수 영역에서의 상관성을 손실시키는 점을 지적하고, MFSC를 채택함으로써 인접 주파수 bin 간의 연속성을 보존한다. MFSC는 DCT 변환을 생략하고 로그 에너지 형태로 직접 계산되므로, 스펙트로그램과 유사한 구조를 유지하면서도 멜 스케일링 효과를 제공한다. 논문은 MFSC의 정적, 1차·2차 시간 미분(델타, 델타‑델타)을 3채널 입력으로 사용하고, 이를 5개의 컨볼루션 블록과 2개의 완전 연결층으로 구성된 CNN에 투입한다. 특히 주파수 축에서 다양한 크기의 max‑pooling을 병렬 적용하고 깊이 방향으로 concat하는 ‘heterogeneous pooling’ 설계는 주파수 해상도를 다중 스케일로 포착해 화자 고유의 스펙트럼 패턴을 더 풍부히 학습하도록 돕는다.
둘째, 단기 스펙트로그램이 포착하지 못하는 장기·초음향적 특성, 즉 프로소딕, 지터, 쉼머와 같은 supra‑segmental 정보를 보완하기 위해 MLP를 도입했다. 18개의 프로소딕 특성을 추출하고, 각각을 2개의 64‑유닛 은닉층과 32‑유닛 출력층을 가진 MLP에 입력한다. 이렇게 얻어진 32‑차원 벡터는 CNN‑FC7 출력(128‑차원)과 결합되어 최종 128‑차원 임베딩을 형성한다.
시암쌍 구조는 두 서브넷이 동일 가중치를 공유함으로써 장치 간 변이와 채널 노이즈에 대한 일반화를 촉진한다. 대비 손실은 같은 화자 쌍에 대해 Euclidean 거리 를 최소화하고, 다른 화자 쌍에 대해서는 마진 m을 초과하도록 거리 를 벌린다. 이때 라벨이 손실에 직접 반영되므로, 전통적인 거리 기반 메트릭보다 판별력이 높은 임베딩 공간을 학습한다.
학습 단계에서는 먼저 CNN을 화자 분류기로 사전 학습해 discriminative한 MFSC 특징을 추출하고, 이후 시암쌍 구조 전체를 대비 손실로 미세 조정한다. 테스트 시에는 전체 발화를 기준으로 프로소딕 특성을 계산하고, 발화에서 무작위로 추출한 여러 짧은 구간을 각각 네트워크에 입력한다. 각 구간 쌍에 대한 거리 값을 평균해 최종 유사도 점수를 산출함으로써, 발화 길이와 장치 차이에 강인한 검증이 가능하다.
이러한 설계는 (1) MFSC와 프로소딕 특성의 상보적 결합, (2) 다중 스케일 주파수 풀링을 통한 풍부한 스펙트럼 표현, (3) 시암쌍 대비 손실에 기반한 장치‑불변 임베딩 학습이라는 세 축에서 기존 MFCC‑MLP 혹은 단일 CNN 모델보다 우수한 성능을 기대한다. 다만, 프로소딕 특성 추출이 전처리 단계에서 추가 비용을 요구하고, 짧은 구간을 다수 샘플링해야 하는 점이 실시간 적용 시 연산량을 증가시킬 수 있다. 또한, 실험 결과가 논문에 상세히 제시되지 않아, 다양한 데이터셋·채널 조건에서의 일반화 정도를 추가 검증할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기