다윈식 데이터 구조 자동 최적화 프레임워크 ARTEMIS
초록
본 논문은 동일한 추상 자료형을 구현하는 여러 구현체를 “다윈식 데이터 구조(DDS)”라 정의하고, 테스트 스위트를 기준으로 실행 시간·메모리·CPU 사용량을 동시에 최적화하는 클라우드 기반 자동 탐색 프레임워크 ARTEMIS를 제안한다. 43개의 Java 프로젝트(다카포 벤치마크 5개, 인기 GitHub 프로젝트 8개, 무작위 샘플 30개)에 적용한 결과, 86 %에서 모든 비기능 목표가 개선되었으며, 평균 개선율은 실행 시간 4.8 %, 메모리 10.1 %, CPU 5.1 %에 달한다. 특히 gson과 xalan 같은 라이브러리에서도 눈에 띄는 성능 향상이 확인되었다.
상세 분석
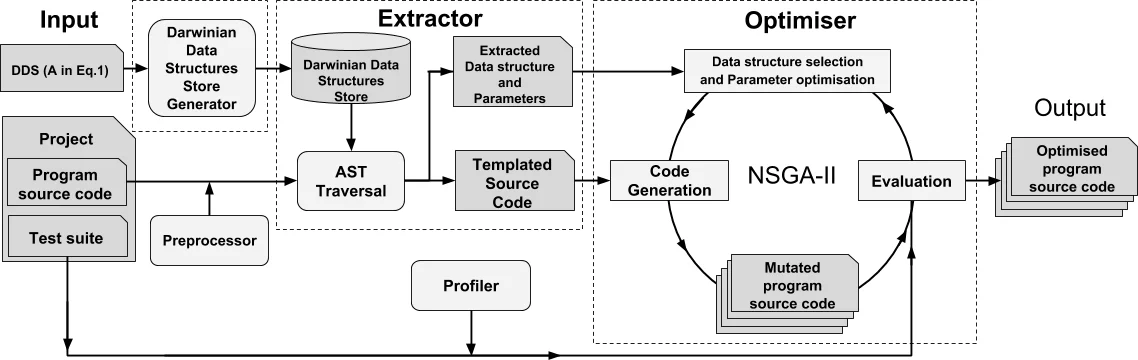
이 논문은 데이터 구조 선택과 파라미터 튜닝이라는 두 차원의 최적화 문제를 하나의 통합 문제로 모델링한다. 먼저 추상 자료형(ADT)을 기준으로 동일 인터페이스를 구현하는 여러 구현체를 “다윈식 데이터 구조(DDS)”라 정의하고, 이러한 DDS가 서로 교체 가능함을 수학적으로 formalize한다. DDS는 Java 컬렉션 API와 같은 표준 라이브러리뿐 아니라 사용자 정의 ADT에도 적용 가능하도록 설계되었으며, 구현체 교체와 동시에 생성자 파라미터(예: ArrayList 초기 용량)까지 탐색 공간에 포함한다.
ARTEMIS의 핵심 아키텍처는 세 부분으로 나뉜다. 첫 번째는 DDS Store Generator(DDSSG)로, 대상 프로그램의 클래스 계층을 분석해 ADT‑Implementation 매핑을 자동 구축한다. 두 번째는 Extractor로, AST를 순회하며 DDS 사용 지점을 식별하고, 해당 위치를 파라미터화된 치환점으로 변환한다. 세 번째는 Optimizer로, 다목적 유전 알고리즘(NSGA‑II)을 이용해 교체 후보와 파라미터 값을 동시에 탐색한다. 이때 적합도 함수는 테스트 스위트 통과 여부와 세 가지 비기능 지표(실행 시간, 메모리 사용량, CPU 사용량)를 다목적으로 평가한다.
검색 과정에서 ARTEMIS는 “가장 해결 가능한 영역”에 집중하기 위해 파레토 전선 상의 해들을 유지하면서도, 변형이 적은 부분에 우선적으로 변이를 적용한다. 이는 대규모 코드베이스에서도 검색 비용을 제한하면서 충분한 탐색 다양성을 확보한다는 장점을 제공한다. 또한, 변형된 코드는 소스‑투‑소스 변환을 통해 원본과 최소한의 차이만을 보이게 하며, 각 변형에 대한 diff를 자동 생성해 개발자가 직접 검토하고 선택할 수 있게 한다.
실험 설계는 43개의 프로젝트에 대해 동일한 테스트 스위트를 기준으로 30번 반복 실행하여 통계적 신뢰성을 확보하였다. 결과는 두드러진데, 37개 프로젝트에서 모든 비기능 목표가 동시에 개선되었으며, 특히 메모리 절감 효과가 평균 10 %를 상회한다. 라이브러리 수준의 개선 사례로는 gson의 메모리 사용량이 16.5 % 감소하고, xalan의 메모리 사용량이 23.5 % 감소한 것이 보고되었다. 이러한 개선은 해당 라이브러리를 사용하는 모든 클라이언트에게 파급 효과를 제공한다는 점에서 실용적 가치가 크다.
한계점으로는 테스트 스위트가 충분히 커버리지를 제공해야 한다는 전제가 있다. 성능 테스트 스위트가 부재한 경우, 단순 회귀 테스트만으로 비기능 지표를 측정하게 되며, 실제 운영 환경과 차이가 발생할 수 있다. 또한, 현재 구현은 Java와 C++에 국한되며, 다른 언어에 대한 DDS Store 구축과 파라미터화 로직이 추가로 필요하다.
전반적으로 이 논문은 데이터 구조 선택이라는 전통적으로 개발자 경험에 의존하던 영역을 자동화하고, 다목적 최적화를 통해 실질적인 성능 향상을 입증함으로써 검색 기반 소프트웨어 공학(Search‑Based Software Engineering) 분야에 중요한 기여를 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기