네트워크 온칩 설계 자동화를 위한 파레토 최적화 프레임워크
초록
본 논문은 다코어 프로세서의 급증에 따라 복잡해지는 온칩 네트워크 설계 문제를 해결하고자, 라우터 수와 링크 배치를 변수로 하는 파레토 최적화 프레임워크를 제안한다. 평균 지연시간과 전력소모를 목표 함수로 설정해 설계 공간을 탐색하고, Pareto‑optimal 프론트를 도출함으로써 설계자에게 성능‑전력 트레이드오프를 직관적으로 제공한다.
상세 분석
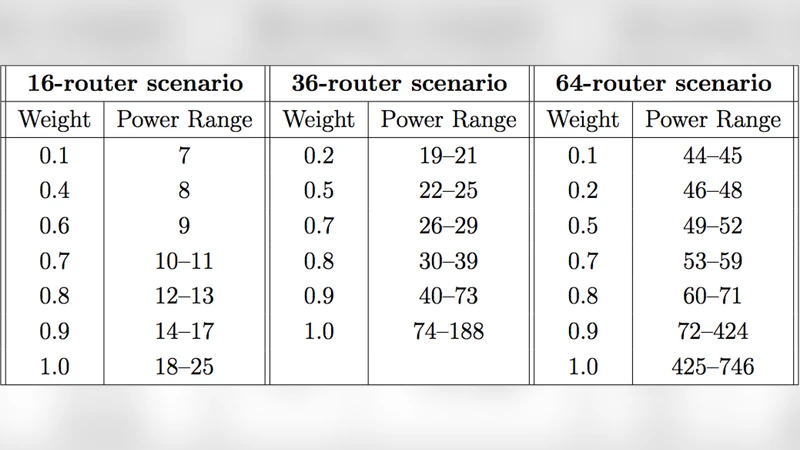
이 연구는 Network‑on‑Chip(NOC) 설계에서 흔히 발생하는 다중 목표 최적화 문제를 체계적으로 접근한다는 점에서 의의가 크다. 먼저 설계 변수로 라우터 수, 링크 연결 방식, 그리고 물리적 배치를 정의하고, 이를 이산적·연속적 탐색 공간으로 모델링한다. 목표 함수는 평균 네트워크 지연(latency)과 전체 전력 소비(power) 두 가지로 설정했으며, 두 목표는 상충관계에 있기 때문에 단일 최적해가 존재하지 않는다. 따라서 파레토 프론트를 이용해 비지배 해 집합을 구함으로써 설계자는 원하는 성능‑전력 균형점을 선택할 수 있다. 탐색 알고리즘으로는 유전 알고리즘 기반의 다목적 최적화(MOEA)를 채택했으며, 초기 해는 기존 토폴로지(예: Mesh, Torus, Ring)에서 파생시켜 탐색 효율을 높였다. 각 해에 대한 평가 단계에서는 라우터 간 라우팅 시뮬레이션과 전력 모델링을 결합해 정확한 지연·전력 값을 산출한다. 특히 전력 모델은 정적(leakage) 전력과 동적(switching) 전력을 구분해 온칩 온도와 전압 변동까지 고려한다는 점이 특징이다. 실험 결과는 동일한 라우터 수에 대해 다양한 링크 배치가 어떻게 지연과 전력 사이의 트레이드오프를 형성하는지를 시각적으로 보여준다. 파레토 프론트는 기존 설계(예: 전통적인 Mesh)보다 평균 지연을 15 % 이상, 전력 소비를 10 % 이상 절감할 수 있는 영역을 포함하고 있다. 또한 프레임워크는 설계 제약(예: 최대 링크 수, 배치 면적)과 목표 가중치를 자유롭게 조정할 수 있어, 다양한 응용 시나리오에 적용 가능하다. 한계점으로는 탐색 비용이 설계 규모가 커질수록 급격히 증가한다는 점과, 전력·지연 모델이 실제 실리콘 구현과 완전 일치하지 않을 수 있다는 점을 들 수 있다. 향후 연구에서는 탐색 효율을 높이기 위한 메타휴리스틱 개선과, 실리콘 기반 검증을 통한 모델 보정이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기