대규모 약라벨 반지도학습 기반 가정 환경 소리 이벤트 탐지
본 논문은 DCASE 2018 Task 4를 소개한다. 약라벨(시간 경계 없이)된 소리 클립과 대규모 비라벨 데이터(도메인 내·외)를 활용해 가정 환경에서의 소리 이벤트를 강한 라벨(시작·종료 시점)로 추정하는 반지도학습 프레임워크를 제시한다. 베이스라인은 CRNN 기반 두 단계 학습으로, 첫 단계는 약라벨로 모델을 학습하고, 이를 이용해 비라벨 데이터를 예측·라벨링한 뒤 두 번째 단계에서 프레임 수준 예측을 수행한다. 평가 결과, 두 번째 단…
저자: Romain Serizel (MULTISPEECH), Nicolas Turpault (MULTISPEECH), Hamid Eghbal-Zadeh
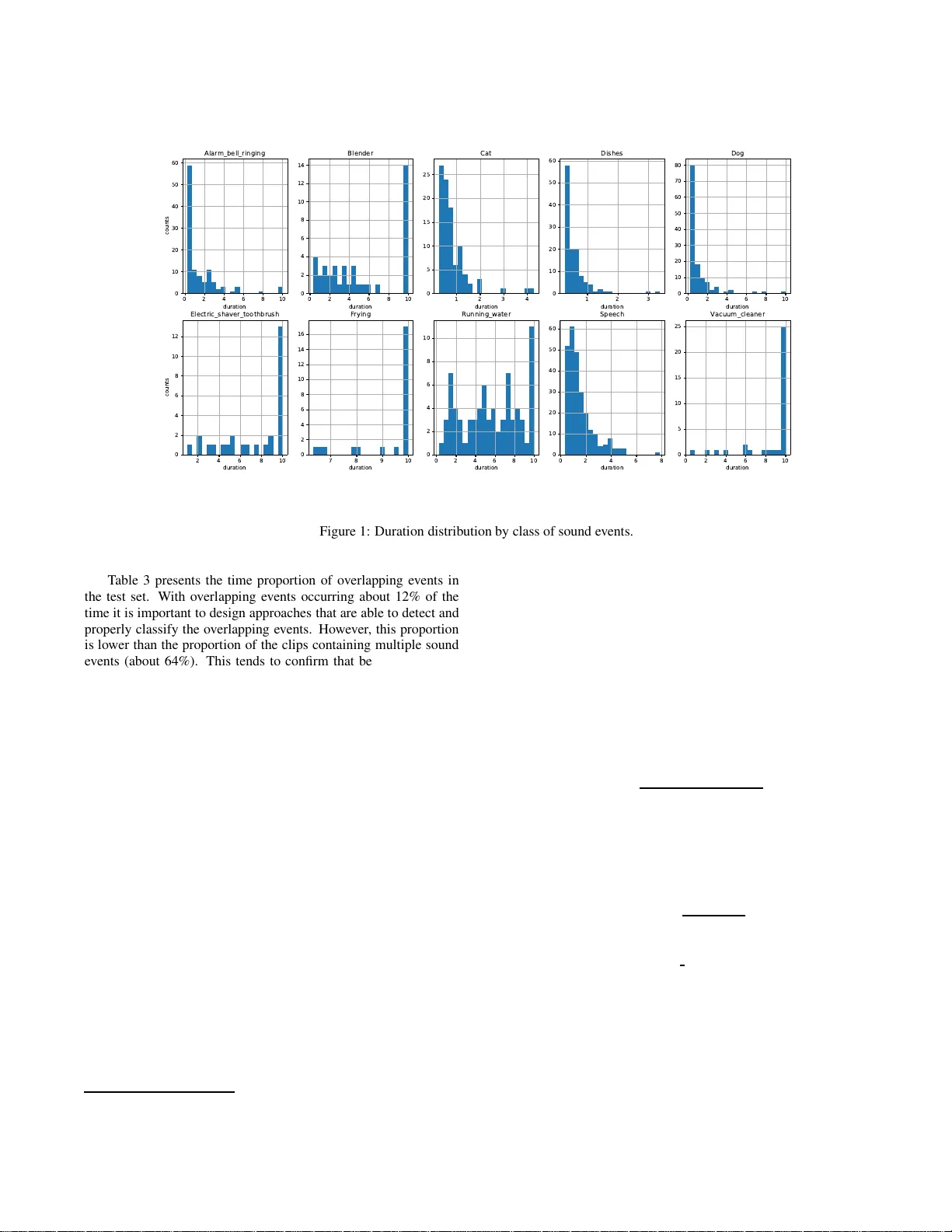
본 논문은 2018년 DCASE 챌린지의 Task 4를 소개한다. 목표는 가정 환경에서 발생하는 다양한 소리 이벤트를 대규모 약라벨 데이터와 비라벨 데이터를 활용해 강한 라벨(시작·종료 시점)로 정확히 탐지하는 것이다. 데이터는 유튜브에서 추출한 10 초 길이의 클립으로 구성된 Audioset의 서브셋이며, 10개의 목표 클래스(Alarm, Blender, Cat, Dishes, Dog, Electric shaver/toothbrush, Frying, Running water, Speech, Vacuum cleaner)로 정의된다.
데이터는 세 부분으로 나뉜다. (1) 약라벨 훈련 세트: 1,578개의 클립(2,244개의 클래스 발생)으로, 인간이 검증·수정한 약라벨이 제공된다. (2) 도메인 내 비라벨 세트: 14,412개의 클립으로, Audioset 라벨이 존재하지만 검증되지 않아 노이즈가 포함될 수 있다. (3) 도메인 외 비라벨 세트: 39,999개의 클립으로, 목표 클래스와 무관한 소리와 대량의 Speech 클립을 포함한다. 테스트 세트는 288개의 클립(906개의 이벤트)으로, 강한 라벨(시작·종료 시점)이 인간 어노테이터에 의해 제공된다. 최소 이벤트 길이는 250 ms이며, 동일 클래스 연속 이벤트 사이 최소 간격은 150 ms로 정의된다.
평가 방식은 이벤트 기반 F1 점수이며, 온셋 콜라 200 ms와 오프셋 허용 오차(200 ms 또는 이벤트 길이의 20 % 중 큰 값)를 적용한다. 최종 점수는 클래스별 F1을 매크로 평균해 산출한다. 이는 클래스 불균형을 보정하고, 모든 클래스에 동등한 중요성을 부여한다.
베이스라인 시스템은 CRNN(Convolutional Recurrent Neural Network) 구조를 사용한다. 입력은 64‑dim log‑mel 스펙트로그램(40 ms 프레임, 50 % 오버랩)이며, 3개의 3×3 컨볼루션 레이어(각 64필터, 주파수 축 풀링 4, 30 % dropout)와 1개의 GRU 레이어(64 유닛, 30 % dropout) 뒤에 시그모이드 활성화 10‑unit Dense 레이어가 연결된다. 첫 번째 단계에서는 약라벨 데이터만 사용해 클립 수준 예측을 학습하고, 이를 통해 도메인 내 비라벨 클립에 대한 pseudo‑label을 생성한다. 두 번째 단계에서는 동일 구조를 사용하되 Dense 레이어를 시간‑분산(Time‑Distributed) 형태로 바꾸어 프레임 수준 출력을 얻는다. 두 단계 모두 500프레임(≈10 s) 입력에 대해 학습하며, 20 %를 검증에 사용한다.
두 번째 단계의 출력에 대해 51프레임(≈1 s) 중위값 필터링을 적용하고, 연속된 양성 구간을 이벤트로 합쳐 시작·종료 시점을 추정한다. 알고리즘은 첫 번째 패스에서 약라벨 모델을 학습·예측하고, 두 번째 패스에서 pseudo‑label을 이용해 프레임 수준 모델을 학습·예측하는 흐름으로 구성된다.
성능 결과는 표 4에 제시된다. 첫 번째 패스에서의 매크로 평균 F1은 7.51 %였으며, 두 번째 패스에서는 14.06 %로 약 두 배 향상되었다. 클래스별로는 ‘Vacuum cleaner’(46.5 %), ‘Electric shaver/toothbrush’(32.4 %), ‘Frying’(31.0 %) 등 길이가 긴 이벤트에서 높은 점수를 기록했지만, ‘Cat’, ‘Dog’, ‘Speech’ 등 짧은 이벤트는 0 %에 가까운 점수를 보였다. 이는 베이스라인이 시간 경계 추정에 약하고, 짧은 이벤트에 대한 민감도가 낮다는 것을 의미한다. 또한 ‘Dishes’ 클래스는 두 번째 패스에서 점수가 감소하는 등 일부 이상 현상도 관찰된다.
논문은 이러한 결과를 바탕으로 향후 연구 방향을 제시한다. 첫째, 약라벨만으로도 프레임 수준의 정확한 시간 경계를 학습할 수 있는 모델 설계가 필요하다. 예를 들어, attention 메커니즘이나 Transformer 기반 시퀀스 모델을 도입해 시간적 컨텍스트를 강화할 수 있다. 둘째, 비라벨 데이터 활용을 위한 보다 정교한 반지도학습 기법(예: consistency regularization, mean‑teacher, pseudo‑label confidence thresholding)이 요구된다. 셋째, 데이터 불균형을 완화하기 위해 클래스 가중치 조정, 오버샘플링, 혹은 focal loss와 같은 손실 함수를 적용할 수 있다. 넷째, 이벤트 중첩을 명시적으로 모델링하는 다중 라벨 시퀀스 예측 또는 멀티‑인스턴스 러닝 접근법이 필요하다. 마지막으로, 후처리 단계에서 단순 중위값 필터링 대신 Viterbi 디코딩, CRF(Conditional Random Field) 등 보다 정교한 시계열 디코딩을 적용하면 온셋 콜라에 대한 오류를 감소시킬 수 있다.
결론적으로, 이 논문은 대규모 약라벨·비라벨 데이터를 활용한 반지도학습 기반 SED 문제를 정의하고, 베이스라인 구현을 통해 현재 기술 수준을 제시한다. 결과는 아직 초기 단계이며, 특히 짧은 이벤트와 정확한 시간 경계 추정에서 큰 개선 여지가 있음을 보여준다. 이는 실제 가정 환경에서의 실시간 모니터링, 스마트 홈, 보조 생활 기술 등에 적용하기 위한 중요한 연구 과제로 남아 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기