지원 벡터 머신을 활용한 암호 랜섬웨어 탐지를 위한 Opcode 밀도 분석
초록
본 연구는 정적 분석을 통해 443개의 Opcode를 추출하고 밀도 히스토그램으로 변환한 뒤, WEKA의 SMO 분류기와 PUK 커널을 이용해 암호 랜섬웨어와 정상 파일을 구분한다. 이진 분류에서 100% 정밀도를, 5개 랜섬웨어 패밀리와 정상 파일을 구분하는 다중 분류에서는 96.5% 정밀도를 달성하였다. 또한 8가지 속성 선택 기법을 평가해 최대 97.7%까지 특성 수를 감소시키면서도 높은 정확도를 유지한다.
상세 분석
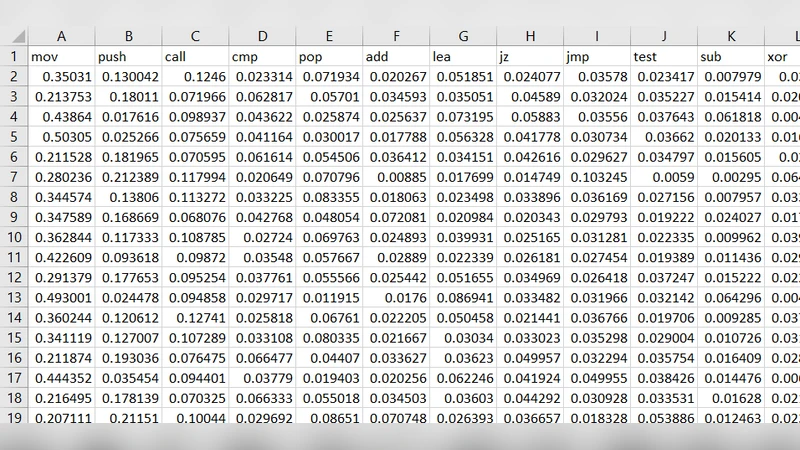
이 논문은 최근 급증하고 있는 암호 랜섬웨어 위협에 대응하기 위해 정적 분석 기반의 머신러닝 모델을 설계하였다. 연구자는 먼저 악성 및 정상 PE 파일을 수집하고, 각 파일에서 전체 443개의 Opcode를 추출하였다. 추출된 Opcode는 파일 전체에 걸친 등장 빈도를 계산해 밀도 히스토그램 형태로 정규화함으로써, 파일 크기에 무관하게 비교 가능한 특성 벡터를 만든다. 이러한 특성 벡터는 고차원(443 차원)이며, 대부분의 차원이 중복되거나 정보량이 낮을 것으로 예상된다.
머신러닝 단계에서는 WEKA 툴킷의 SMO(Support Vector Machine) 구현을 사용했으며, 커널 함수로는 PUK(Polynomial Univariate Kernel)를 선택하였다. PUK 커널은 RBF 커널에 비해 파라미터 조정이 용이하고, 비선형 경계 학습에 강점을 가진다. 실험은 두 가지 시나리오로 나뉜다. 첫 번째는 ‘랜섬웨어 vs 정상 파일’ 이진 분류이며, 두 번째는 5개의 주요 암호 랜섬웨어 패밀리와 정상 파일을 포함한 6클래스 다중 분류이다. 평가 지표는 정밀도, 재현율, F1-score 등을 사용했으며, 특히 정밀도에 중점을 두었다.
이진 분류에서는 100% 정밀도와 100% 재현율을 기록, 즉 모든 악성 파일을 정확히 탐지하면서 정상 파일을 오탐지하지 않았다. 다중 분류에서는 평균 정밀도 96.5%를 달성했으며, 일부 패밀리(예: Ryuk)에서 약간의 오분류가 발생했지만 전체적인 성능은 우수했다.
특성 차원 축소를 위해 8가지 속성 선택 방법을 적용하였다. CorrelationAttributeEval(상관관계 기반 평가)와 Ranker 조합은 59.5%의 특성만 남겨도 거의 동일한 정밀도(≈99.8%)를 유지했다. 반면 CFSSubset(상관 기반 서브셋 선택) 필터는 97.7%까지 특성을 감소시켰지만 정밀도가 94.2%로 약간 감소하였다. 이는 특성 수와 모델 성능 사이의 트레이드오프를 명확히 보여준다. 또한, 특성 선택 후에도 SMO‑PUK 조합은 높은 일반화 능력을 유지함을 확인하였다.
실험 환경은 10‑fold 교차 검증을 적용했으며, 데이터 불균형 문제를 최소화하기 위해 각 클래스당 샘플 수를 균등하게 맞추었다. 결과는 제안된 Opcode 밀도 기반 접근법이 기존 바이트‑시퀀스 혹은 API 호출 기반 방법보다 더 간결하면서도 높은 탐지율을 제공함을 시사한다. 또한, 정적 분석 특성만으로도 암호 랜섬웨어의 변종을 효과적으로 구분할 수 있음을 입증하였다.
댓글 및 학술 토론
Loading comments...
의견 남기기