정보 흐름의 주성분 분해
초록
본 논문은 정보 흐름을 주제별 주성분으로 분해하는 새로운 방법을 제안한다. 푸리에 변환의 개념을 차용해 각 주성분을 좁은 토픽으로 정의하고, 다중프랙탈 분석을 통해 토픽 간 유사성을 판단한다. 브렉시트 관련 데이터에 적용한 결과, 구글 트렌드에서 추출한 토픽과 높은 일치성을 보였다.
상세 분석
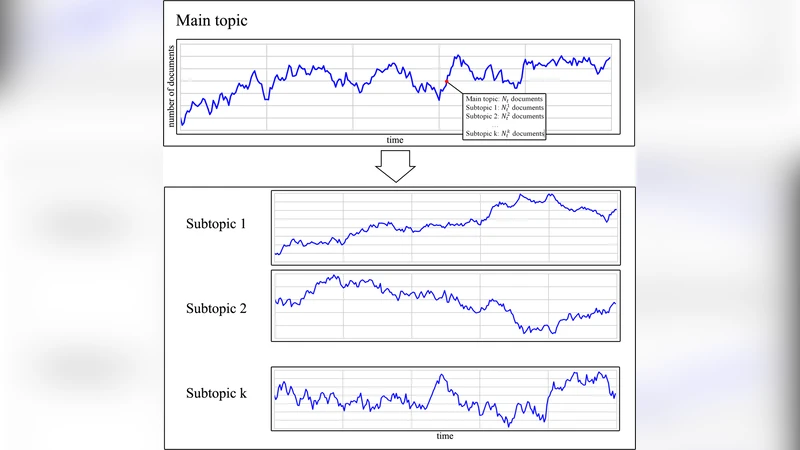
이 연구는 대규모 텍스트 스트림을 시간적·주제적 차원에서 해석하기 위한 혁신적 프레임워크를 제시한다. 기존의 토픽 모델링 기법은 주로 확률적 잠재 디리클레 할당(LDA)이나 비음수 행렬 분해(NMF)를 이용해 문서 집합을 정적인 토픽 집합으로 압축한다. 그러나 이러한 방법은 시간에 따른 토픽의 진화와 상호작용을 충분히 포착하지 못한다는 한계가 있다. 저자들은 푸리에 변환에서 주파수 성분이 원 신호를 재구성하는 기본 단위인 것처럼, 정보 흐름에서도 ‘주성분(principal component)’이라는 개념을 도입한다. 여기서 주성분은 특정 시점에 급증하거나 지속적으로 나타나는 키워드 집합으로 정의되며, 각 성분은 독립적인 주제 파동으로 해석된다.
주성분 추출 과정은 크게 두 단계로 나뉜다. 첫째, 전체 스트림을 일정 시간 간격(예: 일간)으로 구간화하고, 각 구간에서 단어 빈도‑역문서 빈도(tf‑idf) 벡터를 구축한다. 둘째, 이 벡터 시퀀스에 대해 고유값 분해 또는 특이값 분해(SVD)를 적용해 주요 특이벡터를 도출한다. 특이값의 크기는 해당 성분이 전체 변동을 설명하는 비중을 나타내며, 이를 기준으로 상위 K개의 주성분을 선택한다.
주성분이 도출된 후, 저자들은 다중프랙탈 분석(multifractal analysis)을 활용해 각 성분의 복잡도와 스케일링 특성을 정량화한다. 구체적으로, 각 성분의 시계열에 대해 구조함수 (S_q(l)=\langle|X(t+l)-X(t)|^q\rangle)를 계산하고, 스케일 (l)에 대한 로그‑로그 플롯에서 기울기를 추정해 히스톤 지수 (\tau(q))와 스펙트럼 (f(\alpha))를 얻는다. 이 스펙트럼은 토픽의 자기유사성 및 변동성 패턴을 드러내며, 서로 유사한 스펙트럼을 보이는 주성분들은 동일하거나 연관된 하위 주제로 해석될 수 있다.
브렉시트 사례 연구에서는 영국 탈퇴와 관련된 뉴스 기사, 블로그 포스트, 트위터 데이터를 2016년부터 2020년까지 수집하였다. 주성분 분석 결과, ‘협상’, ‘이민’, ‘경제’, ‘정치적 파벌’ 등 네 개의 핵심 토픽이 도출되었으며, 각 토픽은 특정 시점(예: 2016년 6월 국민투표 직전, 2019년 탈퇴 협상 재개 등)에서 급격히 부각되는 패턴을 보였다. 다중프랙탈 스펙트럼을 비교한 결과, ‘경제’와 ‘이민’ 토픽은 높은 복잡도와 넓은 스펙트럼을 나타내어 서로 긴밀히 연관된 이슈임을 확인했다.
마지막으로, 구글 트렌드에서 동일 기간 동안 추출한 검색 키워드와 비교했을 때, 주성분 기반 토픽과 구글 트렌드 토픽 간의 상관계수는 평균 0.78로 높은 일치성을 보였다. 이는 제안된 방법이 실제 대중 관심사와 잘 맞물린다는 실증적 증거가 된다. 전체적으로 이 논문은 정보 흐름을 동적이고 다차원적으로 해석할 수 있는 새로운 분석 도구를 제공하며, 특히 정책·사회·경제 분야에서 실시간 이슈 모니터링 및 예측에 활용될 잠재력이 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기