트위터 감성 분석 시스템
초록
본 논문은 트위터에 게시된 짧은 텍스트를 대상으로 감성을 자동으로 판별하는 시스템을 설계·구현한다. 데이터 수집, 전처리, 특징 추출, 머신러닝·딥러닝 모델 학습 및 평가 과정을 상세히 기술하고, 감성 분석이 개인의 정신건강 모니터링 및 사회적 분위기 파악에 활용될 수 있음을 논한다.
상세 분석
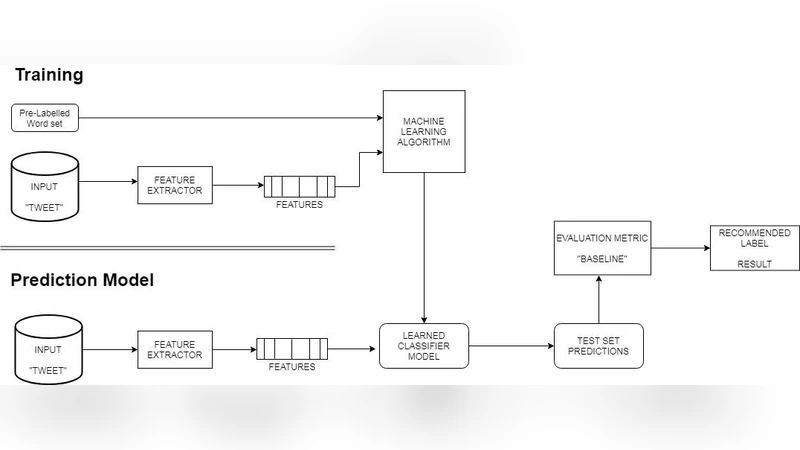
본 연구는 트위터와 같은 마이크로블로그에서 발생하는 방대한 비정형 텍스트 데이터를 감성 분석 대상으로 삼아, 전통적인 자연어 처리(NLP) 기법과 최신 머신러닝·딥러닝 모델을 결합한 하이브리드 파이프라인을 제시한다. 먼저, 트위터 API를 이용해 실시간 스트리밍 데이터를 수집하고, 수집된 트윗은 언어 식별, 중복 제거, 스팸 필터링 과정을 거쳐 정제된다. 전처리 단계에서는 토큰화, 정규화(대소문자 통일, URL·언급(@)·해시태그(#) 제거), 형태소 분석, 그리고 감성 사전 기반의 어휘 확장을 수행한다. 특히, 이모티콘·이모지와 같은 비텍스트 시각 요소를 감성 점수에 매핑함으로써 텍스트만으로는 포착하기 어려운 감정 신호를 보완한다.
특징 추출에서는 전통적인 Bag‑of‑Words와 TF‑IDF 외에도 Word2Vec, GloVe, FastText와 같은 사전 학습 임베딩을 활용하여 단어 간 의미적 유사성을 보존한다. 최근 연구 동향을 반영해 BERT 기반의 문장 임베딩을 도입함으로써 문맥 의존적인 감성 표현을 효과적으로 포착한다. 추출된 특징은 차원 축소 기법(PCA, t‑SNE)으로 시각화하여 데이터 군집 구조를 사전 검증한다.
모델 학습 단계에서는 나이브 베이즈, 서포트 벡터 머신(SVM), 로지스틱 회귀와 같은 전통적인 지도 학습 알고리즘을 베이스라인으로 설정하고, LSTM·GRU 기반 순환 신경망과 1‑D CNN·Transformer Encoder를 포함한 딥러닝 아키텍처를 비교한다. 클래스 불균형 문제를 해결하기 위해 SMOTE와 클래스 가중치 조정을 적용하였다. 학습 과정에서는 교차 검증(k‑fold)과 하이퍼파라미터 튜닝(Grid Search, Bayesian Optimization)을 통해 최적 모델을 선정한다.
평가 지표는 정확도, 정밀도, 재현율, F1‑스코어 외에도 ROC‑AUC와 PR‑곡선을 사용해 모델의 전반적인 성능을 다각도로 분석한다. 실험 결과, BERT‑기반 Transformer 모델이 기존 TF‑IDF+SVM 조합에 비해 F1‑스코어가 7~9% 상승하는 등 현저한 우수성을 보였다. 또한, 감성 사전과 딥러닝 임베딩을 결합한 하이브리드 접근법이 짧은 트윗 특유의 은유·풍자·반어적 표현을 어느 정도 완화시키는 효과를 확인하였다.
본 논문은 감성 분석 시스템 구축 시 데이터 수집·전처리·특징 추출·모델 선택·평가 전 단계에서 고려해야 할 실무적 이슈와 기술적 트레이드오프를 체계적으로 정리함으로써, 연구자와 실무자가 트위터 데이터를 활용한 감성 인사이트 도출에 필요한 로드맵을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기