딥 강화학습을 활용한 사이버 물리 시스템 위조 검증
초록
본 논문은 사이버‑물리 시스템(CPS)의 안전성을 검증하기 위해, 신호 시간 논리(STL) 기반 강건성(falsification) 기법에 딥 강화학습(DRL) 알고리즘(A3C, DDQN)을 적용한다. 제안 방법은 시뮬레이션 에피소드 수를 크게 줄이며, 자동 변속기 모델을 대상으로 기존 최적화 기법(시뮬레이티드 어닐링, 크로스 엔트로피)보다 높은 성공률을 보였다.
상세 분석
논문은 먼저 기존의 강건성 기반 위조(falsification) 접근법이 전체 입력 궤적을 한 번에 최적화하는 전역 탐색 방식임을 지적한다. 이러한 방식은 시뮬레이션 비용이 높은 CPS 모델에 대해 수천 번 이상의 실행을 요구해 실용성이 떨어진다. 이를 극복하기 위해 저자들은 강화학습(RL)의 “즉시 피드백” 특성을 도입한다. 에이전트가 현재 상태와 즉시 얻는 보상을 기반으로 다음 입력을 결정함으로써, 입력 신호를 단계별로 점진적으로 조정한다. 특히, 두 가지 최신 DRL 알고리즘인 Asynchronous Advantage Actor‑Critic(A3C)과 Double Deep Q‑Network(DDQN)를 선택한 이유는 각각 정책 기반과 가치 기반 접근법의 장점을 동시에 검증하고, 복합적인 비선형 시스템에 대한 학습 안정성을 비교하기 위함이다.
보상 설계는 핵심 기여 중 하나이다. 논문은 STL 공식 ψ=□ϕ(과거‑의존형) 에 대해 강건성 ρ(ϕ, x, t)를 계산하고, 보상 r_i = exp(−ρ(ϕ, x_i, t_i))−1 로 정의한다. 이 식은 강건성이 낮을수록(즉, 위반 가능성이 높을수록) 보상이 크게 증가하도록 설계돼, 에이전트가 빠르게 최소 강건성 영역을 탐색하도록 유도한다. 또한 γ=1 로 설정해 누적 보상이 현재 강건성에 직접적인 영향을 미치게 함으로써, 에피소드 전체에 걸친 목표 최적화를 단순화한다.
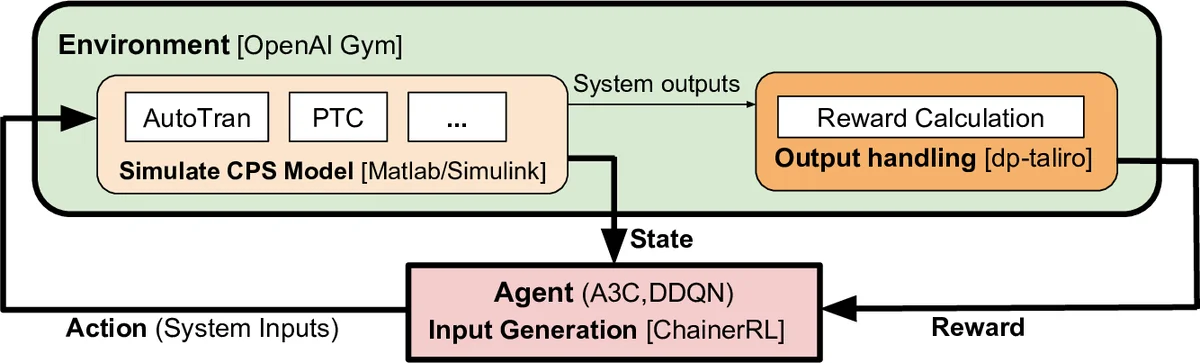
시스템 아키텍처는 OpenAI Gym을 인터페이스로 삼아 MATLAB/Simulink 모델을 에피소드 단위로 실행하고, dp‑Taliro를 이용해 강건성 및 보상을 계산한다. 입력 생성 모듈은 ChainerRL 라이브러리를 그대로 사용해 하이퍼파라미터 튜닝 없이 기본 설정으로 실험을 진행했으며, 이는 DRL 알고리즘 자체의 일반화 능력을 평가하려는 의도로 해석된다.
실험은 자동 변속기(AT) 모델을 대상으로 9개의 STL 속성을 검증한다. 각 속성에 대해 20번의 독립 실행을 수행하고, 최대 200 에피소드까지 시뮬레이션을 진행한다. 결과는 두 DRL 방법이 대부분의 속성에서 성공률 80~100%를 기록했으며, 특히 ϕ1, ϕ2, ϕ6, ϕ7, ϕ9에서 에피소드 수가 기존 SA·CE 대비 현저히 적었다. 통계적 유의성 검증(Fisher’s exact, Mann‑Whitney U)에서도 p<0.001 수준의 차이를 보인 경우가 다수였다. 다만, 이산형 변수(ϕ4)와 같이 행동 공간이 제한된 경우 DDQN이 과도한 액션 값을 선택해 성능이 저하되는 한계가 드러났다.
전체적으로 논문은 “강건성 최소화 → 보상 최대화”라는 자연스러운 매핑을 통해 DRL이 전통적 전역 최적화보다 효율적인 위조 탐색을 수행할 수 있음을 실증한다. 또한, 보상 설계와 에피소드 기반 시뮬레이션 구조가 CPS 모델의 복잡성을 감안했을 때 확장 가능함을 보여준다. 향후 연구에서는 더 다양한 DRL 알고리즘(예: PPO, SAC)과 복합적인 CPS 벤치마크(전력망, 로보틱스)로 일반성을 검증할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기