음성인식 RNN 적응기법 및 구조 비교 연구
본 논문은 TIMIT 전화 인식 과제를 통해 fMLLR, 다섯 종류의 i‑vector 및 두 종류의 CMN을 포함한 여섯 가지 적응·정규화 기법을 LSTM, GRU, M‑reluGRU, reluGRU 등 다섯 가지 RNN 구조와 결합해 성능을 평가한다. 실험 결과, 기존 피드포워드 NN용으로 설계된 일부 적응 기법은 RNN에 그대로 적용했을 때 기대 이하의 PER 향상을 보였으며, 특히 i‑vector의 온라인/오프라인 방식과 스피커/발화 단위…
저자: Jan Vanek, Josef Michalek, Jan Zelinka
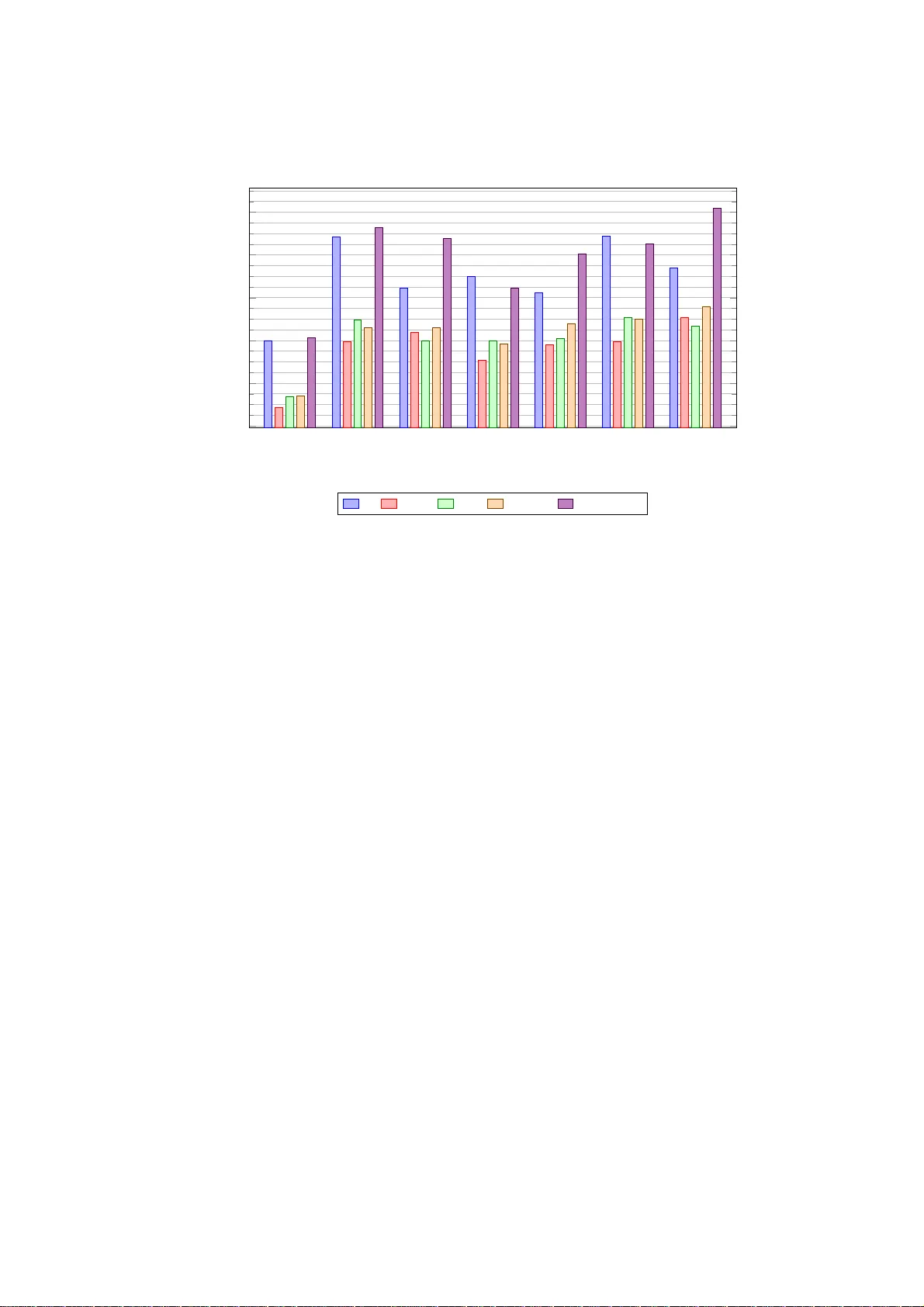
본 연구는 최신 음성 인식 분야에서 RNN 기반 음향 모델이 차지하는 비중이 급증함에 따라, 기존 피드포워드 신경망에 최적화된 적응 및 정규화 기법이 RNN에 얼마나 효과적인지를 체계적으로 검증하고자 한다. 이를 위해 저자들은 TIMIT 전화 인식 과제를 실험 플랫폼으로 선택했으며, TIMIT는 630명의 화자, 5.4시간 분량의 음성 데이터를 포함하고 있어 작은 규모이지만 전화 수준에서의 인식 정확도를 평가하기에 충분한 표준 벤치마크이다.
**실험 설계**
1. **데이터 전처리 및 특징**: Kaldi의 TIMIT s5 레시피를 기반으로 MFCC(13차원)와 그 1차·2차 차분(Δ, ΔΔ)을 결합해 40차원 LDA 변환 특징을 추출했다. 이후 fMLLR 변환을 적용해 스피커 적응을 수행했으며, CMN(발화별·스피커별)도 별도로 저장했다.
2. **적응 기법**: (a) fMLLR – HMM‑GMM 기반의 선형 변환으로, 모든 NN 구조에 동일하게 적용 가능하도록 사전 학습 단계에서 추정하였다. (b) i‑vector – 총 5가지 변형을 구성했다. 온라인/오프라인 추출 방식, 스피커 단위·발화 단위 구분, 학습·테스트 단계에서의 사용 여부를 조합해 5개의 실험군을 만들었다. i‑vector 추출을 위해 2048차원의 UBM을 학습하고, EM 기반 변환을 통해 100차원 벡터를 얻었다.
3. **신경망 구조**: (i) 피드포워드 DNN – 8개의 은닉층, 각 2048개의 ReLU 뉴런, 드롭아웃 0.2, 입력은 11프레임을 스택해 440차원으로 구성. (ii) LSTM – 4개의 은닉층, 각 1024개의 셀, 출력 시차 5, 동일한 드롭아웃 적용. (iii) GRU – 표준 2‑게이트 구조, 동일한 층·유닛 수. (iv) M‑reluGRU – 리셋 게이트를 제거하고 활성화를 ReLU로 교체한 변형. (v) reluGRU – 표준 GRU에 ReLU 활성화를 적용한 변형. 모든 RNN은 동일한 학습 스케줄을 사용했으며, 초기 단계는 Adam(배치 512)으로 빠른 수렴을 도모하고, 이후 3단계 SGD(배치 128, 학습률 1e‑3→1e‑5)로 미세 조정했다.
4. **학습 및 평가**: 각 실험은 무작위 초기화와 확률적 경사 하강에 따른 변동성을 최소화하기 위해 10번 반복 수행했으며, 평균 전화 오류율(PER)과 표준편차를 보고했다. 평가에는 39개의 전화 라벨을 사용했으며, Viterbi 기반 2‑그램 디코더를 적용해 기존 Kaldi WFST 디코더보다 높은 정확도를 확보했다.
**주요 결과**
- **fMLLR**은 모든 모델에서 PER을 평균 0.6~0.9% 포인트 감소시켰으며, 특히 RNN에서도 피드포워드와 비슷한 적응 이득을 보였다. 이는 fMLLR이 특징 자체를 변환하기 때문에 모델 구조에 독립적인 장점을 갖는다는 것을 확인시켜준다.
- **i‑vector**의 효과는 복합적이었다. 온라인 i‑vector를 학습 단계에 결합했을 때 LSTM과 GRU 모두 약 0.3~0.5% PER 감소를 기록했지만, 오프라인 i‑vector를 테스트에만 적용하면 성능 저하가 나타났다. 이는 작은 TIMIT 데이터셋에서 오프라인 i‑vector가 과적합을 일으키기 쉬운 점을 반영한다. 또한, 스피커 단위 i‑vector가 발화 단위보다 안정적인 성능을 보였으며, 특히 발화 단위 i‑vector는 변동성이 커져 표준편차가 크게 늘어났다.
- **RNN 구조 비교**에서 LSTM이 가장 낮은 PER(≈16.2%)을 기록했지만, M‑reluGRU와 reluGRU도 0.2~0.3% 차이로 근접한 성능을 보였다. 특히 M‑reluGRU는 구조가 단순함에도 불구하고 학습 속도가 약 15% 빨라 실용적 이점을 제공한다. 반면, 표준 GRU는 LSTM에 비해 약간 높은 PER을 보였지만, 메모리 사용량이 적어 경량화가 필요한 환경에 적합하다.
- **피드포워드 DNN**은 가장 높은 PER(≈18.0%)을 보였으며, 적응 기법 적용 시 감소 폭이 가장 크게 나타났다. 이는 DNN이 시계열 정보를 직접 모델링하지 못하기 때문에 적응 기법에 더 크게 의존한다는 점을 시사한다.
**의의 및 한계**
본 논문은 “모든 적응 기법이 RNN에 그대로 적용 가능하다”는 기존 가정을 검증하고, 실제로는 적응 기법 선택이 RNN 구조와 데이터 규모에 따라 달라진다는 중요한 교훈을 제공한다. 특히, i‑vector 기반 적응은 온라인 추출과 스피커 수준 적용이 가장 안전하며, 변형 GRU 계열은 경량화와 성능 사이에서 좋은 균형을 제공한다는 점에서 실무 적용 가능성을 높인다. 다만, 실험이 TIMIT라는 작은 데이터셋에 국한되었으며, 대규모 코퍼스나 복잡한 언어 모델을 포함한 실험에서는 결과가 달라질 수 있다. 향후 연구에서는 더 큰 데이터셋, 다국어 환경, 그리고 최신 Transformer 기반 모델과의 비교를 통해 적응 기법의 일반성을 검증할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기