UniParse 범용 그래프 기반 파싱 툴킷
초록
**
UniParse는 파이썬으로 구현된 그래프 기반 의존 구문 분석 툴킷으로, 인코더·디코더·손실 함수·배치 전략 등 모든 구성 요소를 고도로 모듈화하고 Cython으로 최적화하여 빠른 실험과 재현성을 제공한다. 기존의 희소 특징 파서와 최신 신경망 파서를 동일한 인터페이스에서 비교·확장할 수 있다.
**
상세 분석
**
이 논문은 그래프 기반 의존 구문 분석기의 핵심 구성 요소를 ‘인코더(Γ)’, ‘파라미터(λ)’, ‘디코더(h)’라는 세 가지로 추상화하고, 이를 파이썬 클래스와 Cython 모듈로 구현한 UniParse 프레임워크를 제안한다. 가장 큰 특징은 모듈 간 의존성을 최소화한 설계이다. 인코더와 파라미터를 하나의 객체로 통합함으로써, 희소 특징 기반 파서는 인코더가 고정된 피처 벡터를 제공하고, 신경망 파서는 학습 가능한 임베딩을 제공한다는 차이를 자연스럽게 포괄한다.
UniParse는 고수준 API와 저수준 모듈 두 가지 사용 방식을 제공한다. 고수준 API는 CustomParser와 같은 래퍼 클래스를 통해 디코더, 손실 함수, 옵티마이저, 배치 전략만 지정하면 전체 파서를 즉시 실행할 수 있게 하며, 코드 라인 수를 크게 줄인다. 반면 저수준 모듈은 사용자가 직접 Cython 구현된 Eisner 알고리즘이나 Chu‑Liu‑Edmonds(CLE) 디코더, 다양한 배치 전략(버킷, 고정 길이 패딩, 클러스터링 기반 배치) 등을 선택·조합하도록 허용한다.
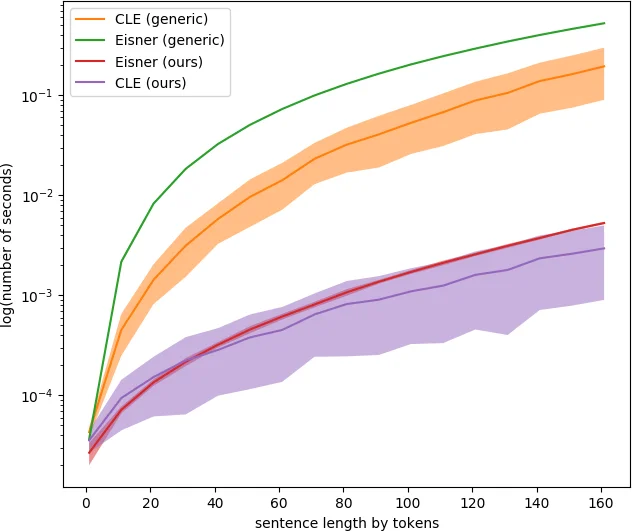
성능 측면에서 논문은 자체 벤치마크를 제시한다. 동일한 무작위 점수 행렬에 대해 Cython 구현이 파이썬 구현보다 10배 이상 빠른 디코딩 속도를 보였으며, 특히 Eisner 알고리즘과 CLE의 최적화 버전이 각각 1.5초와 1.8초 정도로 전체 데이터셋을 처리한다. 이는 대규모 코퍼스에서 실시간 파싱이 필요한 연구에 큰 장점이다.
평가 모듈도 세심하게 설계되었다. 논문은 UAS/ LAS 계산 시 구두점 제거와 라벨 프리픽스 매칭 두 가지 옵션을 명시적으로 제공한다. 구두점 정의는 Unicode 표준을 따르며, 라벨 프리픽스 매칭은 CoNLL‑2017 스크립트와 동일하게 구현돼 기존 연구와의 비교가 정확히 이루어질 수 있다.
또한 UniParse는 MSTparser(희소 특징), Kiperwasser & Goldberg(2016) 신경망 파서, Dozat & Manning(2017) 신경망 파서를 재현한 설정을 기본 제공한다. 실험 결과는 원 논문에서 보고된 성능과 거의 일치하거나 약간 차이 나는 수준이며, 이는 구현이 정확히 재현되었음을 의미한다. 특히, 신경망 파서는 10회 반복 실험 평균을, MSTparser는 단일 실행 결과를 제시해 재현성을 강조한다.
전반적으로 UniParse는 재현 가능성, 모듈성, 속도라는 세 축을 모두 만족시키는 툴킷으로, 기존에 파서 구성 요소를 별도로 구현해야 했던 불편함을 크게 해소한다. 연구자는 새로운 인코더(예: ELMo, TCN)나 손실 함수만 추가하면 즉시 전체 파이프라인에 적용할 수 있어, 설계 실험을 빠르게 수행하고 결과를 공정하게 비교할 수 있다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기