외국인 영어 억양 자동 보정 및 발음 패턴 학습
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
**
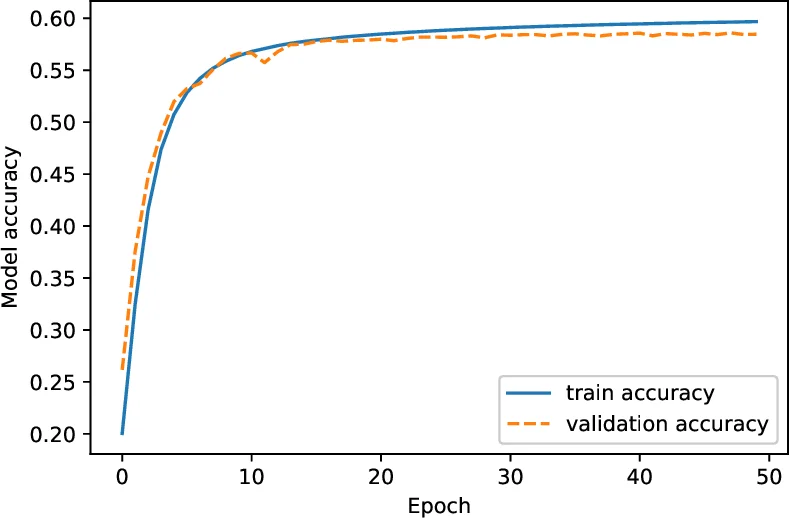
본 논문은 소규모 억양 데이터에서 음운 규칙을 자동으로 추출하고, 이를 이용해 CMU 발음 사전의 단어들을 억양 변형으로 100만 건 생성한다. 생성된 데이터로 시퀀스‑투‑시퀀스 RNN을 학습시켜 억양이 섞인 발음 문자열을 표준 미국식 발음으로 복원하도록 하였으며, 테스트 셋에서 59 %의 정확도를 기록하였다.
**
상세 분석
**
이 연구는 억양 인식·보정이라는 두 가지 핵심 문제에 접근한다. 첫 번째는 “억양 일반화(phonological generalization)”를 자동으로 도출하는 통계 모델이다. 저자들은 GMU Speech Accent Archive에서 2 511개의 오디오와 239개의 민족 코드가 포함된 소규모 데이터셋을 활용한다. 각 억양 샘플을 GAE(General American English) 기준과 비교해 삽입·삭제·대체 현상을 추출하고, 69개의 대표 단어에 대해 사운드‑별 변환 확률을 구축한다. 이 확률 테이블은 “
댓글 및 학술 토론
Loading comments...
의견 남기기