주파수 스펙트럼 위상 복원을 위한 von Mises 딥러닝
본 논문은 진폭 스펙트로그램만을 이용해 위상 스펙트로그램을 복원하는 새로운 방법을 제안한다. von Mises 분포를 조건부 확률 모델로 채택한 심층 신경망(DNN)을 학습시키고, 그룹‑딜레이 손실을 추가함으로써 기존 Griffin‑Lim 알고리즘보다 자연스러운 음성을 생성한다. 실험 결과는 제안 방법이 위상 및 그룹‑딜레이 예측 정확도와 청취 품질 모두에서 우수함을 보여준다.
저자: Shinnosuke Takamichi, Yuki Saito, Norihiro Takamune
본 논문은 음성 및 오디오 신호 처리에서 흔히 사용되는 진폭 스펙트로그램만을 가지고 위상 스펙트로그램을 복원하는 새로운 딥러닝 기반 방법을 제시한다. 기존에 널리 쓰이는 Griffin‑Lim 알고리즘은 진폭을 고정하고 반복적으로 STFT와 역STFT를 수행해 위상을 추정한다. 하지만 초기 위상이 무작위로 설정되기 때문에 합성된 음성에 인공적인 reverberation과 phasiness가 나타나는 단점이 있다. 이러한 문제를 해결하고자 저자들은 두 가지 주요 전략을 도입한다.
첫 번째 전략은 위상이 2π 주기의 주기적 변수라는 점에 착안해, 원형 확률 모델인 von Mises 분포를 사용한다. von Mises 분포는 평균 방향 µ와 집중도 κ라는 두 파라미터로 정의되며, 확률 밀도는 exp(κ cos(y – µ)) / (2π I₀(κ)) 형태이다. 여기서 I₀는 수정 베셀 함수이다. 논문은 DNN을 조건부 확률 모델로 설계하여, 입력 진폭 스펙트로그램 x를 받아 각 프레임·주파수 bin에 대한 µ̂ (예측 위상)를 출력하도록 한다. 학습 목표는 음의 로그우도 –log P(y|µ̂,κ) 를 최소화하는 것이며, κ는 고정하거나 학습되지 않는다. 이로부터 도출된 손실 함수는 L_ph = –∑_f cos(y_f – µ̂_f) 로, 실제 위상과 예측 위상의 코사인 차이를 최소화한다. 이 손실은 2π 정수배 차이에 대해 동일한 최소값을 갖기 때문에, 위상이 주기성을 갖는 특성을 자연스럽게 반영한다.
두 번째 전략은 위상 자체보다 그룹‑딜레이(phase의 주파수 미분)가 진폭 스펙트럼과 더 강한 상관관계를 가진다는 사실을 이용한다. 그룹‑딜레이는 Δy_f = –(y_{f+1} – y_f) 로 근사되며, 이는 음성 신호가 all‑pole 필터 모델로 표현될 때 로그 진폭 스펙트럼과 직접 연결된다. 따라서 그룹‑딜레이를 정규화 목표에 포함시키면, 모델이 진폭 정보를 보다 효과적으로 활용할 수 있다. 논문은 그룹‑딜레이 손실 L_gd = –∑_f cos(Δy_f – Δµ̂_f) 를 정의하고, 이를 위상 손실과 가중치 α로 결합한 다중 과제 손실 L = L_ph + α L_gd 를 사용한다. α는 0.1 로 설정되어, 그룹‑딜레이가 보조적인 정규화 역할을 하도록 한다.
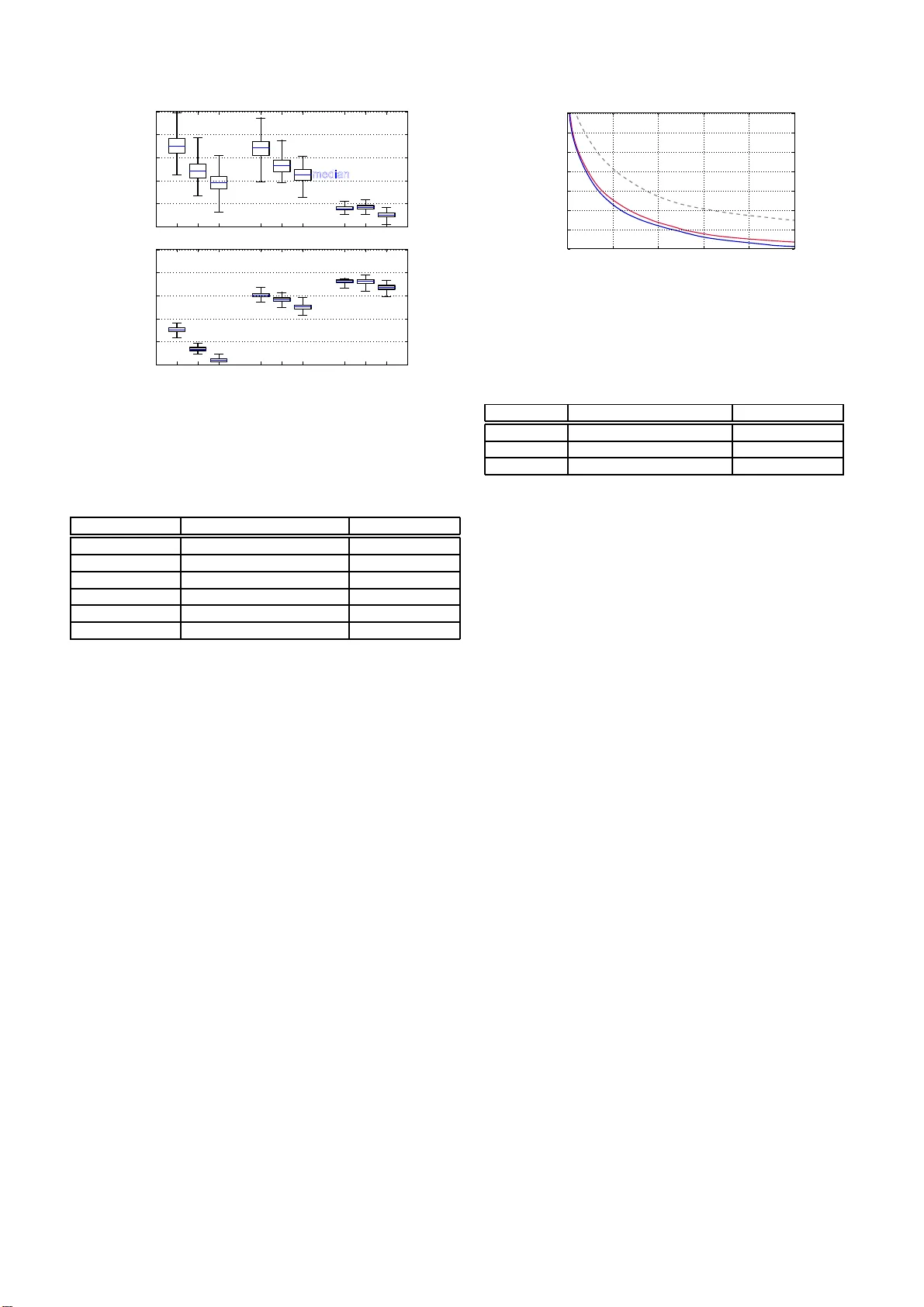
실험은 일본어 여성 화자 데이터셋(JSUT) 5,000개의 훈련 음성과 300개의 평가 음성을 사용했다. 16 kHz 샘플링, 25 ms 윈도우, 5 ms 홉, 512‑point FFT를 적용했으며, 입력 특징은 현재 프레임과 ±2 프레임의 로그 진폭 스펙트럼을 결합한 벡터이다. DNN은 3개의 1024‑unit gated linear unit(GlU) 은닉층과 선형 출력층으로 구성되었으며, AdaGrad(learning rate 0.001)로 최적화하였다. 비교 대상은 기존 Griffin‑Lim과 세 가지 변형(PH, GD, PH+GD)이며, 각 방법은 0‑2 kHz, 0‑4 kHz, 0‑8 kHz 대역까지 위상을 직접 예측하고 나머지는 무작위 위상을 사용한다. 예측 후에는 100회 반복 Griffin‑Lim을 적용해 위상을 정제한다.
예측 정확도는 코사인 거리로 평가했으며, PH(2 kHz)에서는 0.15~0.31 사이, 대역이 넓어질수록 정확도가 감소한다. 반면 GD는 모든 대역에서 PH보다 낮은 코사인 거리를 보이며, 특히 그룹‑딜레이를 직접 예측하는 능력이 뛰어나다. PH+GD는 두 손실을 동시에 학습함으로써 위상과 그룹‑딜레이 모두에서 중간 수준의 정확도를 달성한다.
청취 품질 평가는 30명의 청취자를 대상으로 AB 선호 테스트를 수행했으며, 각 쌍당 10개의 샘플을 300번 청취했다. 결과는 모든 변형이 Griffin‑Lim보다 유의하게 높은 선호도를 보였고, 특히 PH+GD가 가장 높은 점수를 기록했다(p < 10⁻⁹). 대역별 비교에서는 0‑4 kHz 예측이 0‑2 kHz보다 현저히 좋았으며, 0‑8 kHz와 비슷한 수준을 유지했다. 이는 인간 청각이 0‑4 kHz 대역에 가장 민감함을 반영한다는 해석이 가능하다. 또한, DNN이 예측한 위상을 Griffin‑Lim으로 정제했을 때 코사인 거리와 로그 스펙트럼 수렴도 모두 개선되었으며, 정제되지 않은 위상은 청취 품질이 크게 떨어졌다.
논문은 또한 von Mises 분포의 일반화 형태인 cardioid·wrapped Cauchy 분포를 언급하며, 향후 비대칭 분포나 혼합 모델을 활용해 위상의 비대칭성이나 다중 모드 특성을 더 잘 포착할 가능성을 제시한다. 현재 모델은 예측 위상이 2π 배수 범위 밖으로 약간 확산될 수 있지만, 히스토그램 분석 결과 그 정도는 제한적이며 실용적인 수준을 유지한다.
결론적으로, 본 연구는 주기적 변수에 적합한 확률 모델(von Mises)과 그룹‑딜레이 기반 정규화 손실을 결합함으로써, 기존 신호 처리 기반 위상 복원 방법보다 더 정확하고 자연스러운 음성 합성을 가능하게 한다는 점에서 의미가 크다. 향후에는 더 복잡한 분포 모델링, 시퀀스‑와이즈 구조(LSTM/Transformer) 적용, 그리고 실시간 시스템으로의 확장 등이 연구 방향으로 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기