정밀의학 용어 표준화를 위한 통제 어휘 구축
초록
본 논문은 정밀의학 분야에서 발생하는 다양한 생물학적 데이터와 용어를 통합·표준화하기 위해 Precision Medicine Vocabulary(PMV)라는 통제 어휘 체계를 구축한 연구이다. UMLS 기반의 데이터 통합 방법을 적용해 10개의 주요 의미 유형(해부학 구조, 유전자, 변이 등)으로 분류하고, 1,372,967개의 개념과 4,567,208개의 용어를 수집·정제하였다. PMV는 기존 UMLS 대비 유전자·변이·경로 등 정밀의학 핵심 영역에서 더 높은 커버리지를 제공한다.
상세 분석
이 연구는 정밀의학이라는 고도로 융합된 분야에서 데이터 표준화의 필요성을 명확히 제시하고, 실제 구현 방안을 체계적으로 제시한다. 먼저 정밀의학의 정의와 목표를 재조명하고, 기존 UMLS가 다중 종·다중 언어를 포괄하지만 정밀의학 특유의 분자 수준 메커니즘을 충분히 반영하지 못한다는 한계를 지적한다. 이를 보완하기 위해 PMV는 ‘해부학 구조, 유전자, 유전자 제품, 변이, 세포, 질병, 표현형, 생물학적 경로, 생물학적 기능, 화학·약물’이라는 10대 의미 유형을 핵심 축으로 선정하였다.
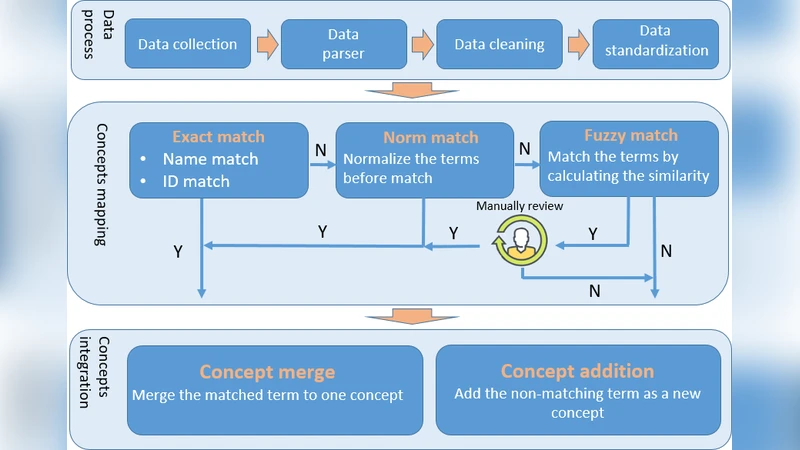
데이터 수집 단계에서는 UMLS 메타쓰레드스와 52개의 주요 어휘원을 선별하고, 인간·영어 데이터만을 남겨 정밀의학 지식베이스(PMKB)의 요구에 맞추었다. 특히 MeSH, NCIt, SNOMED CT와 같은 포괄적 어휘와 HGNC, OMIM, HPO, DrugBank, RxNorm 등 도메인 특화 데이터베이스를 병합함으로써 폭넓은 커버리지를 확보했다.
통합 과정에서는 정확 매칭, 정규화 매칭(Norm tool 활용), 퍼지 매칭, 그리고 전문가 검증이라는 4단계 매칭 파이프라인을 구축하였다. 정규화 단계에서는 소유격 제거, 구두점 공백 변환, 불용어 삭제, 소문자 변환, 어휘 토큰화 및 알파벳 순 정렬을 수행해 문자열 변형에 강인한 매칭을 가능하게 했다. 퍼지 매칭 후 상위 5개 후보를 전문가가 검토·선택함으로써 자동화와 인간 검증의 균형을 맞췄다. 이 절차를 통해 DrugBank에서 4,571개의 신규 약물 개념과 150,629개의 용어를, NCBI Gene과 ClinVar에서는 각각 21,172개의 유전자 개념·220,328개의 용어, 294,712개의 변이 개념·316,630개의 용어를 추가하였다.
PMV의 식별 체계는 UMLS의 MCID(Concept ID), MAID(Term ID), MTID(Type ID)를 차용·단순화했으며, 각 개념은 최소 하나의 용어와 연결되고, 우선순위에 따라 선호 용어를 지정한다. 의미 유형 조직에서는 UMLS와 기존 어휘의 의미 유형을 재활용하고, 하위 계층은 직접 매핑·통합해 ‘Subclass_of’ 관계를 유지한다.
성능 평가에서는 동일 10대 의미 유형에 대해 PMV와 UMLS의 개념 수를 비교했으며, 유전자(66,022 vs 46,948), 변이(320,672 vs 25,715), 경로(2,157 vs 0) 등에서 PMV가 현저히 높은 커버리지를 보였다. 반면 해부학 구조, 세포, 생물학적 기능 등 전통적인 의학 영역에서는 UMLS가 더 많았다. 이는 PMV가 정밀의학 핵심 영역에 특화된 강점을 가지면서도, 기본 의학 영역에서는 아직 보완이 필요함을 시사한다.
향후 계획으로는 의미 유형의 세분화, 새로운 도메인 어휘(예: Pathway Commons) 추가, 용어 간 관계와 속성 주석 강화, 자동화된 통합 도구 개발, MySQL 기반 데이터베이스를 다양한 포맷(예: RDF, JSON)으로 공개하는 방안을 제시한다. 전반적으로 PMV는 정밀의학 데이터 통합을 위한 실용적인 인프라를 제공하며, 향후 임상·연구 현장에서 데이터 상호운용성을 크게 향상시킬 잠재력을 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기