POS 태깅 향상을 위한 다중작업 학습과 문자 수준 단어 표현
초록
본 논문은 BiLSTM 기반 POS 태거에 문자‑레벨 피드포워드 임베딩을 도입하고, 사전학습된 워드벡터와 결합한 뒤, 이웃 라벨 예측이라는 새로운 보조 손실을 적용해 영어와 러시아어에서 정확도와 학습 속도를 동시에 개선한 연구이다.
상세 분석
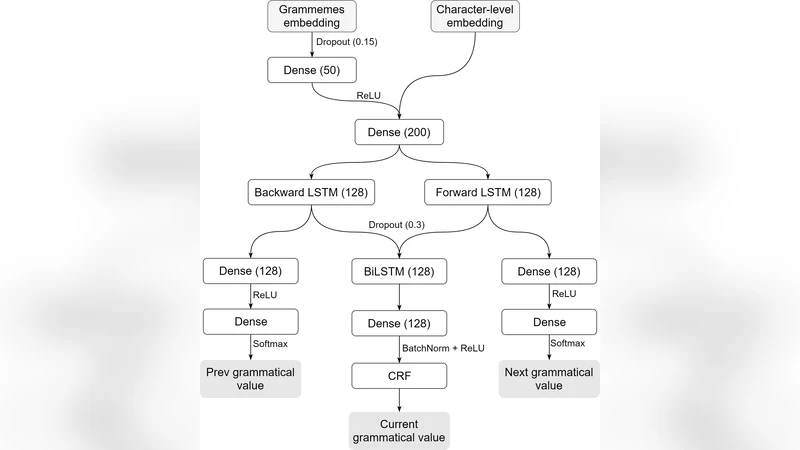
이 연구는 기존 BiLSTM‑CRF 구조를 기본 모델로 삼고, 단어 수준의 정적 임베딩 대신 문자 수준의 동적 표현을 설계한다. 문자 레벨 표현은 각 단어를 문자 시퀀스로 분해하고, 이를 고정 길이 벡터로 변환하기 위해 다층 피드포워드 신경망(FFNN)을 사용한다. 이 방식은 전통적인 CNN‑기반 문자 임베딩보다 파라미터가 적고, 병렬 연산이 용이해 학습 속도가 크게 향상된다. 또한, 사전 학습된 워드2벡터 혹은 FastText와 같은 외부 정적 임베딩을 초기화값으로 활용해 문자‑레벨 FFNN을 미리 훈련시킴으로써, 어휘 정보와 형태소 정보를 효과적으로 결합한다.
보조 작업으로 도입된 이웃 라벨 예측(auxiliary neighbor label prediction) 손실은 현재 토큰의 POS 라벨뿐 아니라 바로 앞·뒤 토큰의 라벨을 동시에 예측하도록 모델을 강제한다. 이는 라벨 간 전이 확률을 학습하도록 유도해, CRF와 같은 전통적 전이 모델 없이도 시퀀스 내 의존성을 포착한다. 실험 결과, 이 손실은 학습 초기에 손실 감소 속도를 가속화하고, 최종 F1 점수를 평균 0.3~0.5%p 상승시켰다.
다국어 실험에서는 영어와 러시아어 두 코퍼스를 사용했으며, 러시아어는 풍부한 형태소 변화를 가지는 언어 특성상 문자‑레벨 표현의 효과가 더욱 두드러졌다. 특히, 어휘 외 OOV(Out‑Of‑Vocabulary) 단어에 대해 문자 임베딩이 큰 이점을 제공해, 전체 정확도 향상에 크게 기여했다.
전체적으로 이 논문은 (1) 효율적인 문자‑레벨 피드포워드 임베딩 설계, (2) 외부 정적 임베딩과의 사전학습 결합, (3) 라벨 이웃 예측이라는 새로운 다중작업 손실 도입이라는 세 축을 통해 POS 태깅 성능과 속도를 동시에 개선한 점이 주목할 만하다.
댓글 및 학술 토론
Loading comments...
의견 남기기