노이즈 강인 파형 사인파 회귀 기반 F0 추정
본 논문은 잡음이 섞인 음성에서 기본 주파수(F0)를 정확히 추정하기 위해, 원시 파형을 입력으로 받아 단일 사인파로 회귀하는 RNN 모델을 제안한다. 기존의 분류 기반 방법이 갖는 주파수 해상도 한계를 극복하고, -10 dB~+10 dB 구간에서 기존 최고 성능 트래커(PEFAC)와 최신 DNN 기반 방법들을 35 %·15 % 이상 능가한다.
저자: Akihiro Kato, Tomi Kinnunen
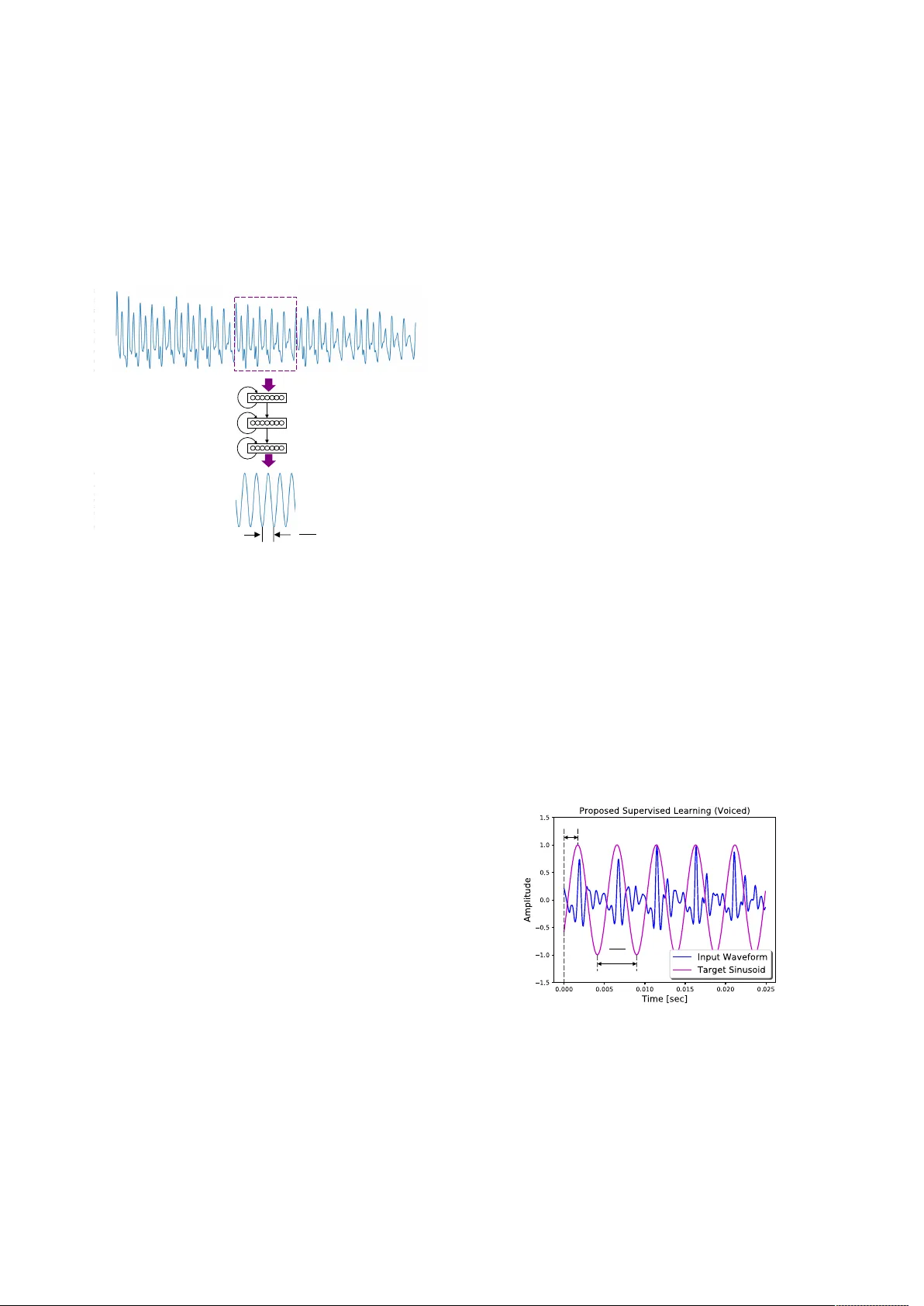
본 논문은 음성 신호의 기본 주파수(F0)를 정확히 추정하는 새로운 방법을 제시한다. 기존의 F0 추정 기술은 크게 두 갈래로 나뉜다. 첫 번째는 RAPT, YIN과 같은 전통적인 시간‑도메인 알고리즘으로, 높은 정확도를 보이지만 잡음에 취약하다. 두 번째는 PEFAC과 같은 로그‑주파수 도메인 필터링 기법으로, 잡음에 어느 정도 강인성을 갖지만 여전히 저 SNR(특히 0 dB 이하)에서 성능이 급격히 저하된다. 최근에는 DNN, CNN, RNN 등을 이용해 스펙트럼 혹은 멜‑계수를 입력으로 하여 F0를 “프레임‑별 주파수 상태 분류” 문제로 전환하는 접근이 활발히 연구되었다. 그러나 이러한 분류 기반 방법은 사전 정의된 주파수 셀 수에 의해 해상도가 제한되고, 양자화 오차와 클래스 불균형 문제에 직면한다.
이를 극복하고자 저자들은 “파형‑대‑단일 사인파 회귀”라는 전혀 새로운 프레임워크를 고안했다. 핵심 아이디어는 원시 파형을 그대로 RNN에 입력하고, 출력층을 항등 함수로 두어 연속적인 실수값을 예측하도록 하는 것이다. 학습 단계에서는 각 프레임의 실제 F0에 해당하는 사인파(위상은 입력 파형과 최대 상관을 갖도록 조정)를 목표 신호로 삼아 평균 제곱 오차(MSE)를 최소화한다. 이렇게 하면 모델은 “입력 파형 → 동일 주파수·위상의 사인파”라는 함수적 매핑을 학습하게 되며, 추론 시에는 출력 사인파의 주기를 자동상관(autocorrelation)으로 분석해 F0를 복원한다. 비음성(무음·비유성) 구간에서는 모델이 입력을 그대로 출력하도록 학습시켜, 불필요한 사인파 생성으로 인한 오류를 방지한다.
모델 구조는 다층 RNN(구체적인 셀 타입은 논문에 명시되지 않았지만 LSTM 또는 GRU가 일반적)으로 구성되며, 각 층은 피드포워드와 피드백 연결을 동시에 갖는다. 입력 파형은 프레임 단위(프레임 길이 M)로 나뉘어 시퀀스 형태로 RNN에 공급되고, 현재 프레임을 중심으로 앞뒤 p프레임(논문에서는 p=2)까지의 정보를 동시에 고려한다. 이는 시간적 연속성을 보존하면서 잡음에 대한 강인성을 높이는 역할을 한다. 출력층은 항등 활성화 함수를 사용해 회귀값을 직접 출력한다.
실험은 PTDB‑TUG 코퍼스를 기반으로 NOISEX‑92의 8종(known)·4종(unknown) 잡음을 혼합해 -10 dB부터 +10 dB까지 다양한 SNR에서 수행되었다. 평가 지표는 Gross Pitch Error(GPE)와 Fine Pitch Error(FPE)이며, 제안 방법은 기존 최고 성능 트래커인 PEFAC 대비 GPE를 35 % 이상, FPE를 35 % 이상 감소시켰다. 또한, 최신 파형‑입력 DNN/CNN 기반 모델(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기