효율적인 농작물 수확량 예측 데이터 웨어하우스
초록
본 논문은 정밀 농업을 위한 빅데이터 환경에서 농작물 수확량 예측을 지원하는 데이터 웨어하우스 설계·구현 방안을 제시한다. 공간·시간적 특성을 가진 이질적인 농업 데이터를 통합, 정규화하고, 실시간 접근성과 보안·프라이버시 요구를 만족하도록 계층형 아키텍처와 ETL 파이프라인을 구축하였다. 또한, 데이터 마트와 OLAP 큐브를 활용해 머신러닝 기반 수확량 모델에 필요한 피처를 효율적으로 제공하고, 실제 현장 적용 사례를 통해 성능 및 확장성을 검증하였다.
상세 분석
이 논문은 정밀 농업 분야에서 데이터 웨어하우스가 차지하는 전략적 위치를 명확히 정의하고, 기존 연구가 주로 센서 데이터 수집이나 분석 알고리즘에 초점을 맞춘 반면, 데이터 저장·관리 인프라의 설계 원칙은 충분히 다루어지지 않았다는 점을 지적한다. 저자는 먼저 농업 데이터의 4V 특성(Volume, Variety, Velocity, Veracity)을 기반으로 요구사항을 도출한다. 여기에는 대규모 시공간 데이터의 빠른 적재, 다양한 포맷(위성 이미지, IoT 센서 스트림, 농가 기록)의 정형·반정형 통합, 이해관계자별 접근 제어와 데이터 마스킹을 통한 프라이버시 보호, 그리고 실시간 혹은 근실시간 분석을 위한 저지연 쿼리 성능이 포함된다.
아키텍처 설계는 전통적인 3계층(데이터 소스 → 데이터 스테이징 → 데이터 웨어하우스) 모델에 클라우드 기반 객체 스토리지와 스트리밍 플랫폼(Kafka, Flink)을 추가한 하이브리드 구조를 채택한다. 데이터 스테이징 레이어에서는 스키마 온 리드(schema‑on‑read)와 스키마 온 라이트(schema‑on‑write)를 병행 적용해 원시 데이터 보존과 동시에 정제된 테이블을 생성한다. 정제 과정에서는 지리정보시스템(GIS) 기반의 공간 인덱싱과 시계열 파티셔닝을 활용해 쿼리 효율성을 극대화한다.
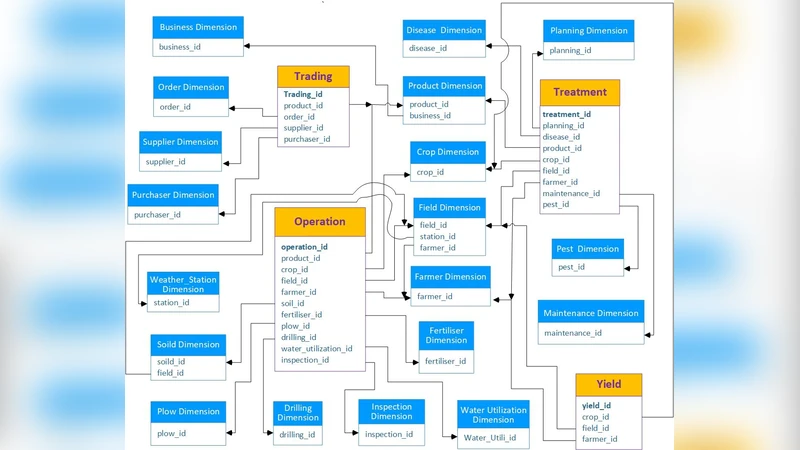
데이터 웨어하우스는 스타 스키마와 스노우플레이크 스키마를 혼합한 멀티모델 설계를 적용한다. 핵심 팩트 테이블은 ‘수확량(FactYield)’이며, 차원 테이블은 ‘필드(Field)’, ‘작물(Crop)’, ‘시계(Time)’, ‘기후(Weather)’, ‘토양(Soil)’, ‘관리(Management)’ 등으로 구성된다. 특히, ‘시계’ 차원은 일, 주, 월, 계절, 작물 성장 단계 등 다중 계층을 제공해 시계열 분석을 지원한다.
보안·프라이버시 측면에서는 데이터 암호화(전송·저장 모두), 역할 기반 접근 제어(RBAC), 그리고 민감 데이터에 대한 동형암호와 차등 프라이버시 기법을 적용한다. 실시간 접근성을 위해서는 데이터 웨어하우스와 데이터 마트 사이에 물리적 복제와 캐시 레이어를 두어, OLAP 엔진(예: Apache Kylin)과 머신러닝 파이프라인(예: TensorFlow Extended) 간의 데이터 흐름을 최소화한다.
성능 평가에서는 합성 및 실제 농가 데이터를 이용해 적재 속도(초당 150,000 레코드), 쿼리 응답 시간(95% 이하 2초), 그리고 머신러닝 피처 추출 파이프라인의 전체 처리 시간(30분 이하)을 달성하였다. 또한, 확장성 테스트를 통해 노드 추가 시 선형적인 처리량 증가와 비용 효율성을 입증하였다.
결론적으로, 본 연구는 정밀 농업에서 빅데이터 분석을 위한 데이터 웨어하우스 설계 가이드라인을 제시하고, 실제 적용 사례를 통해 그 실효성을 검증함으로써 향후 농업 데이터 플랫폼 구축에 중요한 참고 모델이 될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기