멀티모달 주의 메커니즘을 활용한 종단형 오디오·비주얼 대화 시스템
본 논문은 동영상의 시각·청각 정보를 멀티모달 주의 기반 특징으로 통합하고, 이를 종단형 시퀀스‑투‑시퀀스 모델에 결합해 영상에 대한 대화를 생성하는 AVSD(오디오·비주얼 씬‑어웨어 대화) 시스템을 제안한다. 새롭게 구축한 9천 개 동영상·대화 데이터셋을 활용해 실험했으며, 멀티모달 주의가 적용된 비디오 특징이 대화 응답 품질을 크게 향상시킴을 입증한다.
저자: Chiori Hori, Huda Alamri, Jue Wang
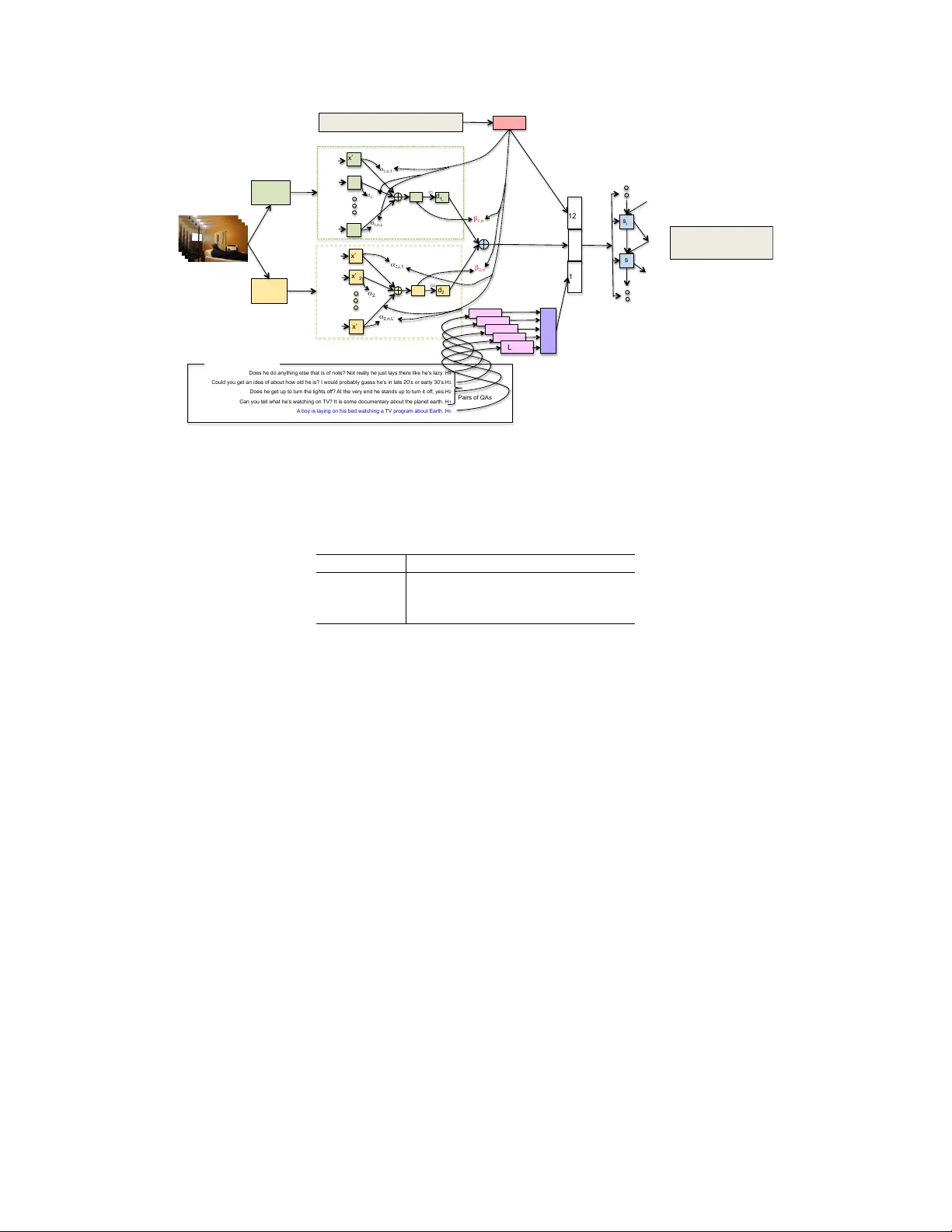
본 논문은 동영상의 시각·청각 정보를 동시에 활용해 인간과 자연스러운 대화를 나눌 수 있는 ‘오디오·비주얼 씬‑어웨어 대화(AVSD)’ 시스템을 제안한다. 연구 동기는 기존 대화 시스템이 정적 이미지나 텍스트 기반 입력에만 의존해, 실제 환경에서 발생하는 동적인 상황을 이해하고 설명하는 데 한계가 있다는 점이다. 이를 극복하기 위해 저자들은 세 가지 주요 기여를 제시한다. 첫째, 9,000여 개 동영상에 대해 두 명의 AMT 작업자가 10라운드 질문‑답변(QA) 대화를 진행한 새로운 데이터셋을 구축하였다. 질문자는 영상 전체를 보지 못하고 첫·중·마지막 프레임만을 제공받아, 제한된 시점 정보만으로 상황을 추론하도록 설계되었다. 두 번째 기여는 멀티모달 주의 기반 비디오 특징 추출 방법이다. VGG‑16을 이용한 정적 이미지 특징, C3D와 I3D‑rgb·flow를 이용한 동작·시간적 특징, 그리고 MFCC·SoundNet·VGGish를 이용한 오디오 특징을 각각 시퀀스 형태로 추출한 뒤, 질문 인코딩과 각 모달리티의 컨텍스트 벡터를 결합해 동적 가중치 β_k를 계산한다. 이 가중치는 질문 내용에 따라 자동으로 변동되어, 시각적 질문에는 이미지·동작 특징에, 청각적 질문에는 오디오 특징에 높은 주의를 할당한다. 세 번째 기여는 이러한 멀티모달 특징을 Hierarchical Recurrent Encoder‑Decoder(HRED) 구조에 통합한 종단형 대화 모델이다. 질문, 멀티모달 영상·오디오 특징, 그리고 이전 QA 쌍으로 구성된 대화 히스토리를 각각 LSTM 인코더에 입력하고, 이들의 출력을 하나의 컨텍스트 벡터 g(av)로 결합한다. 디코더 LSTM은 매 단어 생성 시점마다 이 컨텍스트를 재삽입함으로써, 질문‑특징 연관성을 지속적으로 반영한다. 모델은 Beam Search를 통해 최적의 응답 시퀀스를 탐색한다.
실험은 두 단계로 진행되었다. 첫 번째 단계에서는 MSVD, MSR‑VTT, Charades 세 데이터셋에 대해 멀티모달 주의 기반 특징을 이용한 비디오 캡션 성능을 평가하였다. I3D‑rgb·flow와 VGGish를 결합한 경우, Naïve Fusion(단순 연결) 대비 BLEU‑4, METEOR, CIDEr 점수가 각각 평균 3~5% 상승하였다. 두 번째 단계에서는 새로 만든 AVSD 데이터셋에 모델을 적용했다. 멀티모달 주의 모델은 기존 이미지‑기반 대화 모델 대비 답변 정확도와 자연스러움에서 평균 1.5~2.0 포인트 향상을 보였으며, 특히 “무엇을 하고 있나요?”와 같은 동작 중심 질문에 대해 높은 정확도를 달성했다. 가중치 시각화 결과, 질문 인코딩이 특정 모달리티에 높은 β_k를 부여하는 것이 확인되었으며, 이는 모델이 질문‑모달리티 연관성을 학습했음을 의미한다.
논문의 한계점으로는 (1) 현재 멀티모달 주의가 각 모달리티를 독립적인 시퀀스로 처리하고 가중합하는 구조라, 복합적인 상호작용(예: 동작과 동시에 발생하는 소리)을 완전히 포착하지 못한다는 점, (2) 데이터가 주로 실내 행동(가정용)으로 제한돼 있어 야외·복합 환경에 대한 일반화가 미흡하다는 점을 들었다. 향후 연구 방향으로는 트랜스포머 기반 멀티모달 어텐션을 도입해 장기 의존성을 강화하고, 교차 모달리티 피드백 루프를 구현해 동시 이해 능력을 높이는 것이 제시되었다. 또한 실제 로봇 플랫폼에 배포해 실시간 대화와 상황 인식을 동시에 평가함으로써, 스마트 홈, 차량 내 인포테인먼트, 협동 로봇 등 다양한 응용 분야에 적용 가능한 씬‑어웨어 대화 에이전트를 구현하는 것이 목표이다.
요약하면, 이 논문은 멀티모달 주의 메커니즘을 활용해 동영상의 시각·청각 정보를 효과적으로 통합하고, 이를 종단형 대화 모델에 결합함으로써 동적 장면에 대한 자연스러운 대화 생성이 가능함을 입증한다. 데이터셋 공개와 코드·사전학습 모델 제공을 통해 향후 연구 커뮤니티가 AVSD 분야를 더욱 확장할 수 있는 기반을 마련하였다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기