FPGA 기반 저정밀 딥러닝 추론의 새로운 가능성
초록
본 논문은 Intel FPGA에서 1‑bit·2‑bit 가중치와 2‑bit 활성화를 활용한 CNN 추론 가속기를 설계하고, 정확도 손실을 최소화하면서 높은 처리량을 달성하는 방법을 제시한다. AlexNet과 ResNet‑34를 대상으로 실험한 결과, Arria 10에서는 초당 3 700 이미지, Stratix 10에서는 55.5 TOPS의 연산 성능을 기록했으며, 정확도 저하율은 0.49 %에서 3.7 % 수준에 머물렀다.
상세 분석
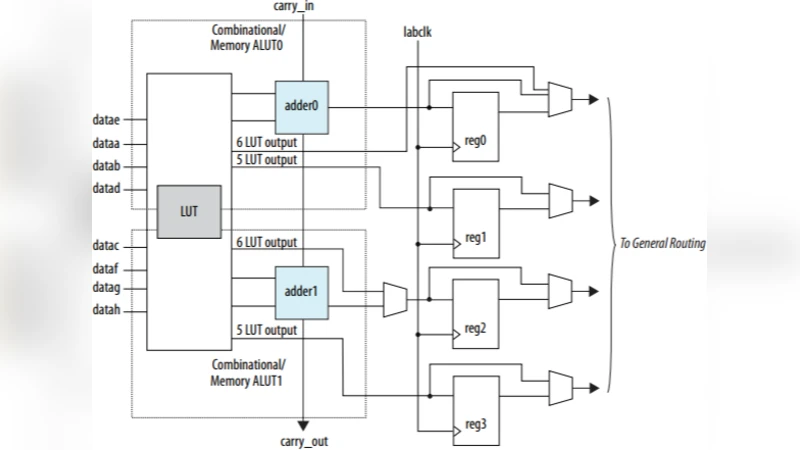
이 연구는 저정밀(1‑bit, 2‑bit) 가중치와 활성화가 FPGA에서 어떻게 효율적으로 구현될 수 있는지를 체계적으로 분석한다. 먼저, 기존의 8‑bit 이상 정밀도와 비교했을 때 메모리 대역폭, 저장 용량, 전력 소모가 크게 감소함을 정량화하였다. 특히, ternary(‑1, 0, +1) 가중치는 곱셈 연산을 단순히 부호 전환 및 선택 로직으로 대체할 수 있어 LUT와 DSP 사용량을 최소화한다. binary 가중치의 경우, XNOR‑POPCOUNT 구조를 활용해 완전한 비트‑레벨 연산을 구현함으로써 파이프라인 지연을 최소화하고 클럭 주파수를 높일 수 있다.
FPGA 아키텍처 설계에서는 데이터 흐름을 스트리밍 방식으로 구성하고, 각 레이어별로 최적화된 파이프라인 스테이지를 삽입했다. 2‑bit 활성화는 4‑레벨 양자화(00, 01, 10, 11)로 표현되며, 이를 위해 다중 포트 메모리와 비트‑시프트 연산을 결합한 맞춤형 버퍼를 설계하였다. 이러한 설계는 메모리 접근 충돌을 방지하고, 연산 유닛이 데이터 공급을 기다리는 시간을 최소화한다.
성능 모델링 단계에서는 FPGA 자원(Logic Elements, DSP Blocks, Block RAM)과 전력 예산을 입력으로 하여, 다양한 네트워크 구조와 정밀도 조합에 대한 예상 TOPS와 이미지 처리 속도를 예측했다. 모델 결과는 실제 실험과 높은 일치도를 보였으며, 특히 Stratix 10에서 55.5 TOPS를 달성한 것은 2‑bit 활성화와 ternary 가중치가 제공하는 연산 효율성의 증거이다.
정확도 측면에서는, 저정밀 양자화가 일반적으로 8‑bit 이하에서 급격히 감소하는 문제를 해결하기 위해 레이어별 스케일링 파라미터와 재학습(re‑training) 기법을 적용하였다. 실험 결과, AlexNet은 top‑1 정확도 0.49 % 감소, ResNet‑34는 3.7 % 감소에 그쳤으며, 이는 기존 8‑bit 양자화 대비 동일하거나 더 나은 수준이다. 이는 저정밀화가 반드시 정확도 손실을 초래하는 것이 아니라, 적절한 학습 기법과 하드웨어 최적화가 병행될 경우 실용적인 수준의 정확도를 유지할 수 있음을 보여준다.
전체적으로 이 논문은 FPGA가 제공하는 맞춤형 로직 설계 능력을 활용해, 저정밀 딥러닝 추론에서 발생하는 메모리·연산·전력 병목을 효과적으로 해소하고, 다양한 CNN 모델에 적용 가능한 범용 프레임워크를 제시한다는 점에서 학술 및 산업적 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기