StarGAN 기반 비병렬 다대다 음성 변환 모델
StarGAN‑VC는 비병렬 데이터만을 이용해 다수의 화자 간 음성 변환을 수행하는 GAN 기반 프레임워크이다. 하나의 생성기와 도메인 분류기를 통해 속성(화자) 라벨을 조건으로 넣어 실시간 수준의 변환을 가능하게 하며, 몇 분 정도의 학습 데이터만으로도 자연스러운 음성을 생성한다. 실험 결과는 기존 VAE‑GAN 기반 방법보다 음질과 화자 유사도에서 우수함을 보여준다.
저자: Hirokazu Kameoka, Takuhiro Kaneko, Kou Tanaka
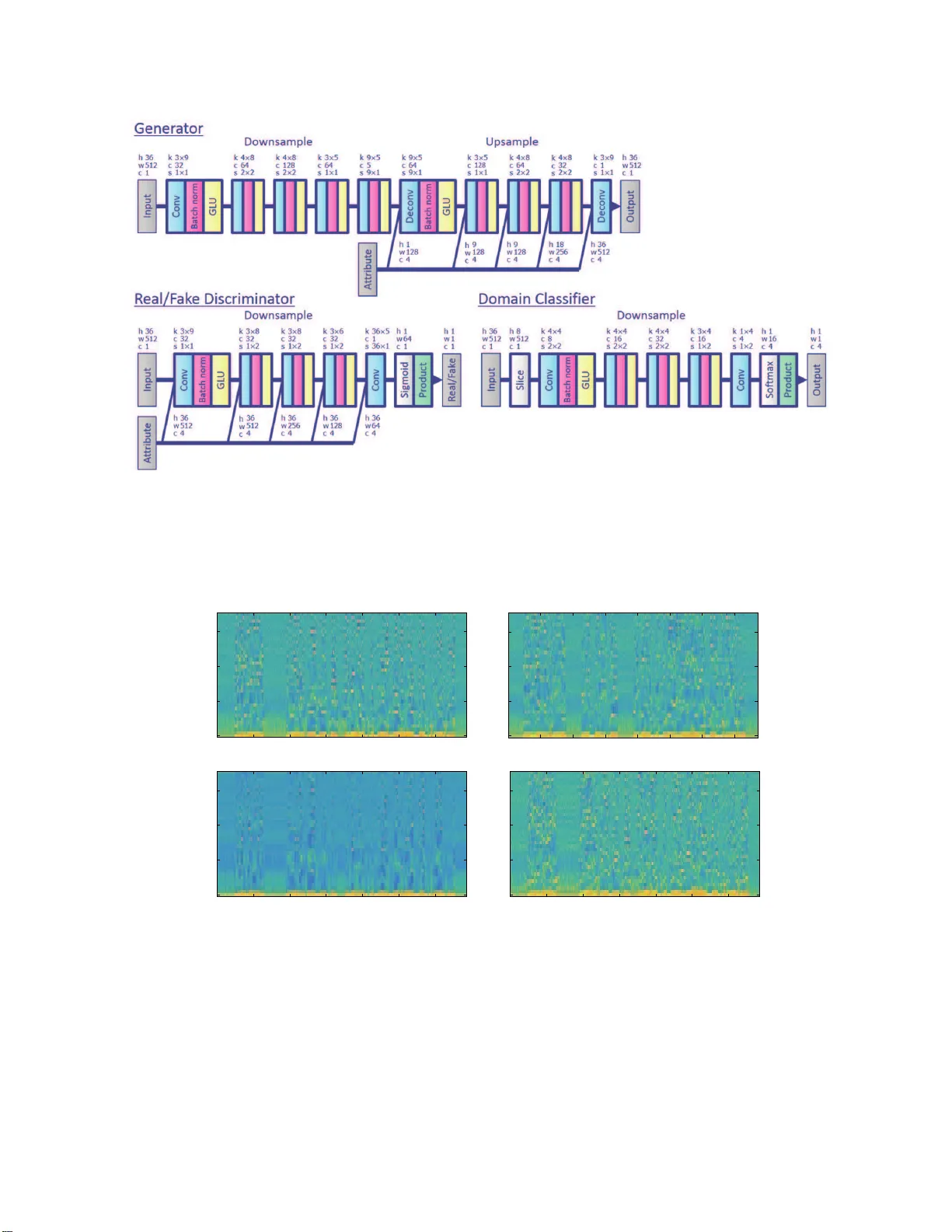
본 논문은 비병렬 다대다 음성 변환(Voice Conversion, VC)을 위해 StarGAN을 기반으로 한 새로운 프레임워크인 StarGAN‑VC를 제안한다. 기존 VC 방법은 대부분 병렬 데이터와 정확한 시간 정렬을 전제했으며, 비병렬 접근법은 품질 저하와 제한된 변환 범위가 문제였다. 저자들은 이러한 한계를 극복하기 위해 (1) 병렬 데이터, 전사, 정렬 절차 없이 학습이 가능한 구조, (2) 하나의 생성기 G와 도메인 분류기 C를 이용해 다수의 속성(화자) 도메인 사이를 동시에 학습, (3) 실시간 수준의 변환 속도와 짧은 학습 시간(몇 분)이라는 실용성을 강조한다.
먼저 기존 CycleGAN‑VC를 리뷰한다. CycleGAN‑VC는 두 개의 매핑 G와 F, 그리고 두 개의 판별기 D_X, D_Y를 사용해 1대1 변환을 수행한다. adversarial loss와 cycle‑consistency loss, identity loss를 결합해 언어 정보를 보존한다. 그러나 다대다 변환을 위해서는 도메인마다 별도의 G‑F 쌍을 학습해야 하며, 파라미터 수가 도메인 수에 따라 급증한다는 단점이 있다.
StarGAN‑VC는 이러한 문제를 해결하기 위해 StarGAN 구조를 차용한다. 입력 음성 특징 x와 목표 속성 라벨 c(원‑핫 인코딩)를 동시에 받아 변환된 특징 ŷ = G(x,c)를 출력한다. 판별기 D는 (y,c) 쌍이 실제인지 가짜인지를 판단하고, 도메인 분류기 C는 특징이 어느 라벨에 속하는지를 예측한다. 학습 목표는 네 가지 손실의 가중합으로 정의된다.
- **Adversarial loss** (L_G^adv, L_D^adv): G가 D를 속여 변환된 특징을 실제와 구분되지 않게 만든다.
- **Domain classification loss** (L_G^cls, L_C^cls): C가 실제와 변환된 특징을 올바른 라벨에 매핑하도록 학습한다. G는 C가 목표 라벨을 부여하도록 유도된다.
- **Cycle‑consistency loss** (L_cyc): G가 변환 후 다시 원래 도메인으로 복원했을 때 입력과 일치하도록 하여 언어적 내용 보존을 강제한다.
- **Identity loss** (L_id): 입력이 이미 목표 도메인에 속하면 변환이 거의 일어나지 않도록 하여 불필요한 변형을 억제한다.
각 손실은 λ_cls, λ_cyc, λ_id 파라미터로 조절된다. 전체 목표는 I_G(G)=L_G^adv+λ_cls L_G^cls+λ_cyc L_cyc+λ_id L_id, I_D(D)=L_D^adv, I_C(C)=L_C^cls 로 정의된다.
특징 추출은 WORLD 분석기를 사용해 스펙트럼 엔벨로프와 MFCC를 얻고, 변환 후에는 스펙트럼 게인 함수를 계산해 원본 스펙트럼에 곱한 뒤 WORLD vocoder로 시간 도메인 신호를 복원한다. 이 방식은 프레임 단위 변환을 유지하면서도 실시간 처리에 적합하도록 설계되었다.
실험에서는 다섯 명의 화자를 대상으로 비병렬 다대다 변환을 수행하였다. 각 화자당 약 5분 정도의 훈련 데이터를 사용했으며, 주관적 청취 테스트(MOS, speaker similarity)에서 StarGAN‑VC가 기존 VAE‑GAN 기반 방법보다 평균 0.2~0.3 점 높은 품질을 보였다. 특히, 변환 속도는 실시간 수준(초당 수천 프레임)으로 구현 가능했으며, 학습 시간도 몇 분에 불과했다.
논문의 주요 기여는 다음과 같다.
1. **단일 생성기로 다대다 매핑**: 속성 라벨을 조건으로 넣어 하나의 네트워크가 모든 도메인 간 변환을 학습함으로써 파라미터 효율성을 크게 향상시켰다.
2. **비병렬 학습**: 병렬 데이터와 정렬 절차 없이도 고품질 변환을 달성했다.
3. **실시간 구현 가능**: 프레임 단위 입력을 그대로 처리하고, 간단한 스펙트럼 게인 기반 복원을 사용해 실시간 변환을 구현했다.
4. **짧은 학습 데이터 요구**: 몇 분 수준의 데이터만으로도 충분히 자연스러운 음성을 생성할 수 있음을 입증했다.
한계점으로는 현재 화자 라벨만을 속성으로 다루고 있어 감정, 억양, 언어 스타일 등 복합적인 특성을 동시에 제어하기 위해서는 라벨 설계와 네트워크 확장이 필요하다. 또한, WORLD 기반 복원은 최신 neural vocoder에 비해 음질이 다소 떨어질 수 있으므로, HiFi‑GAN 등과 결합하면 더욱 자연스러운 결과를 기대할 수 있다.
결론적으로, StarGAN‑VC는 비병렬 다대다 음성 변환 분야에서 파라미터 효율성, 학습 데이터 요구량, 실시간 처리 가능성 측면에서 현존하는 방법들을 뛰어넘는 실용적인 솔루션을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기