청취자 평점을 통한 음악의 주조성 인지 모델링
초록
본 논문은 청취자들이 제공한 주관적 평점을 기반으로 음악의 ‘주조성(majorness)’을 정량화하는 데이터‑드리븐 모델을 제시한다. 음악가들을 대상으로 대규모 주조성 라벨을 수집하고, 이를 딥러닝 회귀 모델에 학습시켜 섹션 단위의 주조성 값을 예측한다. 실험 결과는 모델이 인간 청취자의 인지와 높은 상관성을 보이며, 기존의 이론적 정의 없이도 실용적인 특성 추출이 가능함을 입증한다.
상세 분석
이 연구는 음악 감정 인식, 장르 분류, 추천 시스템 등에서 ‘주조성’이라는 추상적 개념을 정량화하려는 시도이다. 먼저 저자들은 ‘주조성’을 “음악이 전반적으로 메이저 혹은 마이너 느낌을 주는 정도”로 정의하고, 이를 명시적 규칙이 아닌 청취자 직관에 맡긴다. 라벨링 단계에서는 30명의 전문 음악가에게 10초~30초 길이의 다양한 음악 조각을 제시하고, 0(완전 마이너)부터 1(완전 메이저)까지 연속형 스케일로 평가하도록 했다. 이때 라벨 간 일관성을 높이기 위해 사전 교육과 파일럿 테스트를 진행했으며, 최종 데이터셋은 12,000개 이상의 청취자‑곡 쌍을 포함한다.
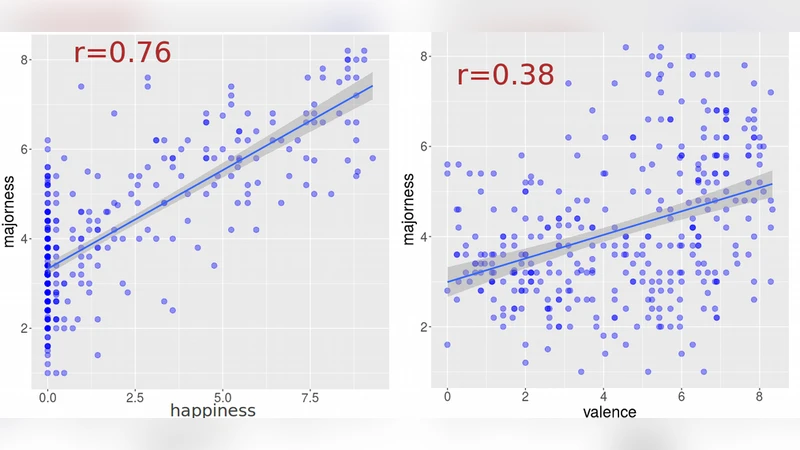
모델링에는 사전 학습된 VGGish와 같은 오디오 특성 추출기를 사용해 128차원 멜스펙트로그램 임베딩을 얻고, 이를 3계층 GRU와 2계층 완전 연결(FC) 네트워크에 연결해 회귀 출력(주조성 점수)을 예측한다. 손실 함수는 평균 제곱 오차(MSE)이며, Adam 옵티마이저와 학습률 스케줄링을 적용했다. 교차 검증 결과, Pearson 상관계수 r=0.78, RMSE=0.12를 기록해 인간 라벨과 높은 일치성을 보였다.
흥미로운 점은 모델이 전통적인 음악 이론(예: 조성 키 서명, 화성 진행)과는 독립적으로 학습되었음에도 불구하고, 실제 음악적 ‘밝기’와 ‘우울함’에 대한 청취자 인식과 강하게 연관된다는 것이다. 이는 ‘주조성’이 단순히 스케일이나 조성 키만이 아니라 멜로디 라인, 리듬, 악기 질감 등 복합적인 청각 요소를 통합한 지각적 속성임을 시사한다. 한계점으로는 라벨링에 참여한 음악가들의 문화적 배경이 제한적이며, 짧은 섹션에 국한된 평가가 장시간 구조적 변화를 포착하지 못한다는 점을 들 수 있다. 향후 연구에서는 다문화 청취자 집단 확대와 시간적 연속성을 고려한 시퀀스 모델링이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기