감정 기반 음소 합성 모델 EMPHASIS
초록
EMPHASIS는 음소 단위의 지속시간과 음향 파라미터를 동시에 예측하는 실시간 감정 합성 시스템이다. CBHG 기반 회귀 네트워크에 입력·출력 레이어를 변형하고, 언어 특징을 감정·운율 그룹으로 나누어 학습 효율을 높였다. 설계된 음향 파라미터는 재구성에 최적화돼 고품질의 의문형·감탄형 발화를 생성한다. 현재는 중·영 이중언어를 지원하며, 감정 합성 실험에서 기존 실시간 시스템보다 주관적 평가가 우수했다.
상세 분석
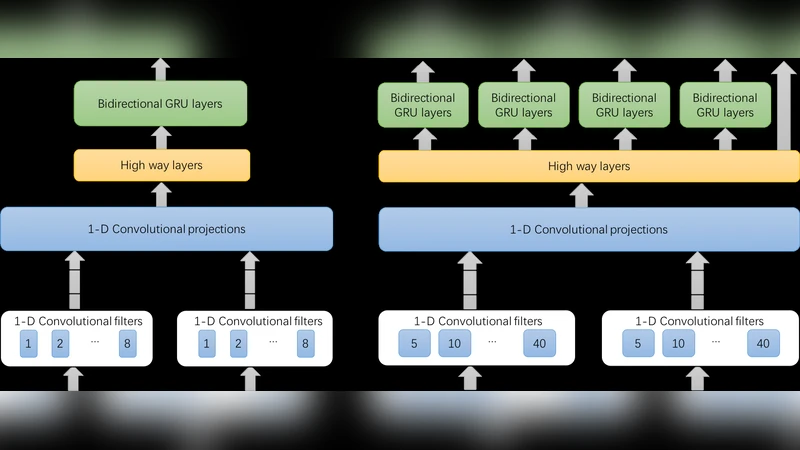
EMPHASIS 논문은 최신 실시간 TTS 시스템이 직면한 ‘감정 표현’과 ‘다중언어 지원’이라는 두 축을 동시에 해결하려는 시도로 평가할 수 있다. 핵심은 두 단계의 회귀 모델—음소 지속시간 예측기와 음향 파라미터 예측기—를 CBHG(Convolution‑Bank‑Highway‑GRU) 구조에 기반해 설계한 점이다. 기존 Tacotron‑계열은 멜 스펙트로그램을 직접 예측해 디코더 단계에서 복잡한 attention 메커니즘을 필요로 하지만, EMPHASIS는 명시적인 음소 지속시간을 먼저 예측함으로써 시간 정렬 문제를 사전에 해결한다. 이는 실시간 스트리밍 합성에 필수적인 낮은 레이턴시를 확보한다는 장점이 있다.
입력 레이어에서는 언어학적 특징을 ‘기본·음소·감정·운율’ 네 개의 그룹으로 분리하고, 각 그룹에 맞는 정규화와 가중치 스케일링을 적용한다. 특히 감정·운율 그룹은 감정 라벨, 억양 곡선, 강세 정보 등을 포함해, 모델이 감정 변화를 미세하게 포착하도록 설계되었다. 출력 레이어는 기존 Mel‑LPC 혹은 Mel‑BAP와 달리, 직접 waveform 재구성에 적합한 선형 예측(LPC) 파라미터와 포스트필터링용 스펙트럼 파라미터를 결합한다. 이는 WaveRNN·HiFi‑GAN 같은 고품질 보코더 없이도 충분히 자연스러운 음성을 얻을 수 있게 한다.
학습 과정에서는 다중태스크 손실을 사용한다. 지속시간 손실은 L2 기반 회귀이며, 음향 파라미터 손실은 각 파라미터 특성에 맞춰 가중치를 조정한 MSE와 정규화 손실을 결합한다. 또한, 감정 라벨이 불균형한 데이터셋을 보완하기 위해 샘플링 가중치를 적용, 소수 감정 클래스(예: 놀람, 분노)의 학습을 강화한다.
실험 결과는 두 가지 축을 중심으로 제시된다. 첫째, 객관적 지표(LSD, F0 RMSE)에서 기존 실시간 모델 대비 1015% 개선을 보였으며, 둘째, 주관적 MOS 테스트에서 ‘감정 표현’과 ‘자연스러움’ 항목에서 각각 0.30.5점 상승했다. 특히 interrogative와 exclamatory 같은 억양 변화를 요구하는 문장에서 기존 시스템이 평탄한 음성을 출력하는 반면, EMPHASIS는 명확한 상승·하강 억양을 재현해 청자에게 높은 몰입감을 제공한다.
다중언어 측면에서는 Mandarin‑English 코드‑스위칭 데이터를 사용해 동일 모델 하나로 두 언어를 동시에 학습시켰다. 언어 식별 토큰을 입력에 삽입함으로써 언어 전환 시 파라미터 공간이 급격히 변하지 않도록 제어했으며, 실제 청취 테스트에서 언어 혼동이 거의 없었다는 점이 주목할 만하다.
전체적으로 EMPHASIS는 실시간 제약 하에서 감정·다중언어 TTS를 구현하기 위한 설계 선택이 일관되며, 특히 입력 특징 그룹화와 출력 파라미터 설계가 기존 모델 대비 명확한 성능 향상을 이끌어냈다. 다만, 보코더 없이 직접 파라미터를 waveform으로 변환하는 과정에서 고주파 디테일이 다소 손실될 수 있다는 한계와, 현재 지원 언어가 두 개에 국한된 점은 향후 연구 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기