단일 모델로 다중 화자 음성 변환, 비병렬 데이터에서 화자와 내용 분리
초록
본 논문은 비병렬 음성 데이터를 이용해 하나의 모델만으로 다수의 목표 화자에게 음성을 변환하는 프레임워크를 제안한다. 자동인코더와 화자 분류기‑1을 통해 화자 정보를 억제한 언어‑내용 잠재 표현을 학습하고, 이를 목표 화자 임베딩과 결합해 디코더가 기본 변환을 수행한다. 이후 GAN 기반 잔차 생성기를 도입해 스펙트로그램의 세부 구조와 자연스러움을 보강한다. 20명의 화자를 대상으로 한 실험에서 전역 분산(Global Variance)과 주관 청취 평가 모두에서 기존 Cycle‑GAN 기반 방법보다 우수한 성능을 보였다.
상세 분석
이 연구는 음성 변환(Voice Conversion, VC) 분야에서 “비병렬 데이터 + 다중 화자”라는 두 가지 난제를 동시에 해결하고자 한다. 기존 Cycle‑GAN 기반 VC는 목표 화자마다 별도의 모델을 훈련해야 하는 한계가 있었으며, VAE 기반 접근법은 프레임 단위 변환에 머물러 인접 프레임 간의 연관성을 충분히 활용하지 못했다. 저자들은 이러한 문제점을 보완하기 위해 두 단계로 구성된 학습 파이프라인을 설계하였다.
첫 번째 단계에서는 자동인코더(AE)를 사용해 입력 스펙트로그램을 언어‑내용만을 담은 잠재 벡터(enc(x))와 화자 임베딩으로 분리한다. 여기서 핵심은 “분류기‑1”을 도입해 enc(x)가 화자 정보를 최소화하도록 역학습(adversarial training)하는 것이다. 구체적으로, 분류기‑1은 enc(x)를 입력으로 화자를 예측하도록 학습하고, 인코더는 이 손실을 최대화함으로써 화자 특성을 억제한다. 동시에 디코더는 enc(x)와 원본 화자 y를 결합해 원본 스펙트로그램을 재구성한다(L_rec). 이렇게 하면 인코더가 화자에 무관한 언어 표현을 추출하면서도 재구성 품질을 유지한다.
두 번째 단계에서는 기본 변환 결과(V₁)만으로는 스펙트로그램이 흐릿해지는(over‑smoothing) 문제를 해결하고자, 잔차 신호를 생성하는 별도 생성기(gen)를 도입한다. 생성기는 고정된 인코더·디코더 출력과 목표 화자 임베딩을 입력받아 미세 구조를 보강한다. 이 생성기는 “판별기‑2 + 분류기‑2”와 경쟁하며 학습된다. 판별기‑2는 실제 스펙트로그램과 생성된 V₂를 구분하는 WGAN‑GP 손실(L_adv)을 사용하고, 분류기‑2는 입력 음성이 어느 화자에 속하는지를 예측한다. 생성기는 자신이 만든 V₂가 목표 화자 y₀에 대해 높은 분류 확률을 갖도록 L_g_cls2를 최소화한다. 따라서 최종 출력 V₂ = V₁ + gen(…)는 원본 내용은 유지하면서 목표 화자의 음색을 더욱 정확히 재현한다.
구현 측면에서는 CBHG 모듈을 기반으로 1‑D 컨볼루션, 픽셀‑셔플 업샘플링, 양방향 GRU 등을 조합했으며, 드롭아웃을 인코더와 분류기에 각각 0.5와 0.3 비율로 적용해 일반화 능력을 강화하였다. 학습 초기에 λ를 0에서 0.01까지 선형 증가시켜 인코더가 급격히 화자 정보를 잃지 않도록 조절한 점도 주목할 만하다.
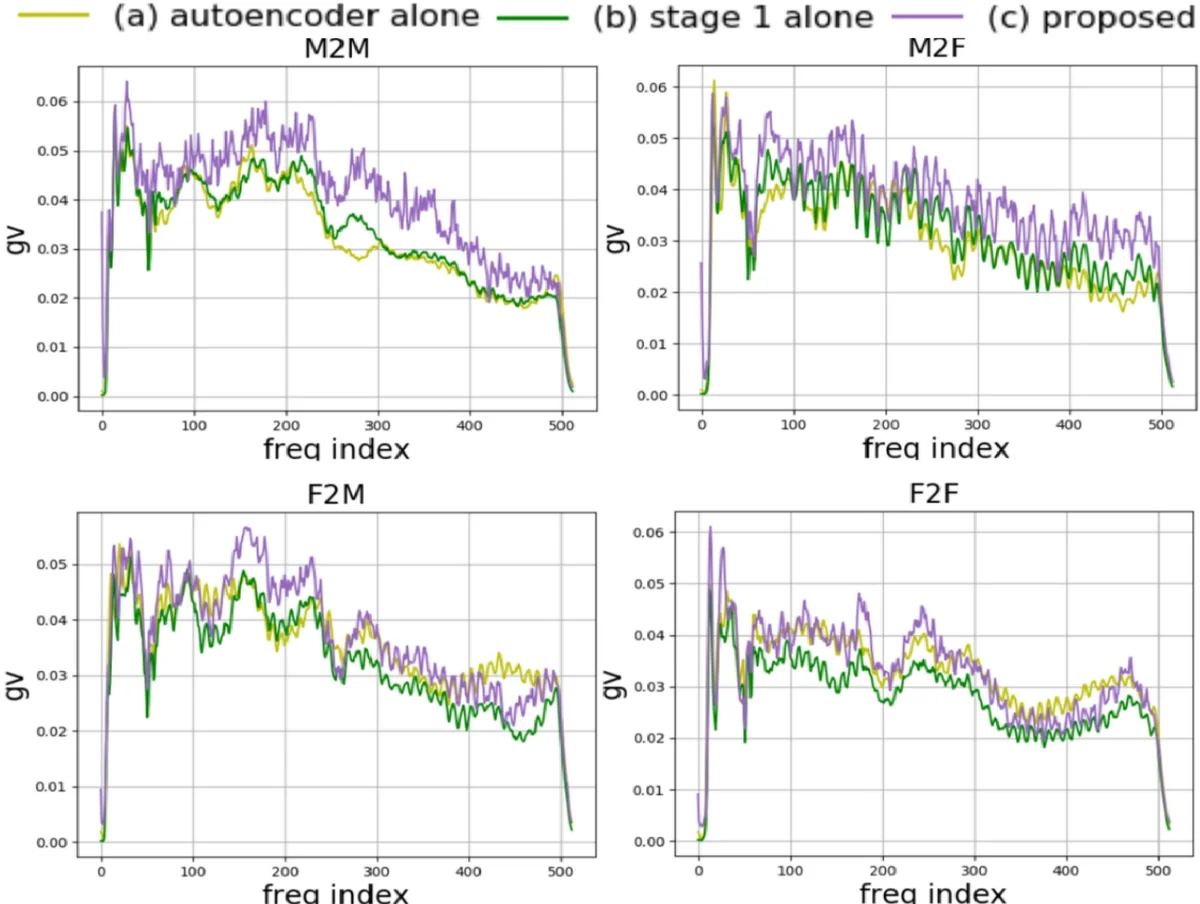
실험은 VCTK 코퍼스에서 20명의 화자(남·여 10명씩)를 선정해 수행되었다. 객관적 평가지표인 전역 분산(GV)은 기존 자동인코더만 사용했을 때보다 Stage 1+분류기‑1, 그리고 최종 Stage 2까지 순차적으로 증가했으며, 제안 방식이 가장 높은 GV를 기록했다. 주관적 청취 테스트에서도 자연스러움과 화자 유사도 측면에서 제안 모델이 Stage 1 단독 및 Cycle‑GAN‑VC 대비 유의미하게 선호되었다.
핵심 기여는 (1) 화자‑독립적 언어 표현을 역학습으로 효과적으로 추출한 자동인코더 구조, (2) 고정된 디코더 위에 잔차 GAN을 겹쳐 스펙트로그램의 세부 디테일을 복원한 두 단계 학습, (3) 단일 모델로 다수의 목표 화자를 지원함으로써 실용적인 다중 화자 VC 시스템을 구현했다는 점이다. 다만, 현재 실험은 20명 화자에 국한되었으며, 더 큰 화자 풀이나 실시간 변환, 다른 언어·방언에 대한 일반화 검증이 향후 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기