다학제 디지털 도서관 메타데이터 자동 풍부화: 의미 기반 태깅 파이프라인
초록
본 논문은 오픈 액세스 과학 논문 메타데이터에 의미 기반 다중 라벨 태깅을 적용하는 파이프라인을 제안한다. 기존의 키워드 기반 검색이 학문 간 용어 차이로 인해 제한되는 문제를 해결하기 위해, (1) TF‑IDF → 밀집 의미 벡터 변환을 통한 논문 특징 추출, (2) 토픽별 긍정·부정 샘플을 이용한 One‑vs‑All 분류기 학습, (3) BabelNet 기반 동의어 집합(synset)으로 확장된 ElasticSearch 쿼리, (4) 두 랭킹을 평균‑랭크 방식으로 융합하여 최종 메타데이터를 예측한다. ISTEX 데이터와 Web of Science 토픽 33개를 활용한 실험에서 기존 동의어 확장 방식 대비 F1 점수가 11% 향상되고, 연산 복잡도도 크게 낮아 대규모 디지털 라이브러리 적용 가능성을 입증하였다.
상세 분석
이 연구는 메타데이터 부족으로 인한 학문 간 정보 검색 장벽을 의미론적 접근으로 해소하고자 한다. 먼저, 논문의 제목과 초록을 결합한 텍스트를 TF‑IDF로 벡터화한 뒤, 사전 학습된 Word2Vec 혹은 FastText와 유사한 임베딩 모델을 이용해 100~600 차원의 밀집 벡터로 변환한다. 이 단계는 고차원 희소 표현을 의미적 유사성을 보존하는 저차원 공간으로 압축함으로써 이후 분류기의 학습 효율을 크게 높인다.
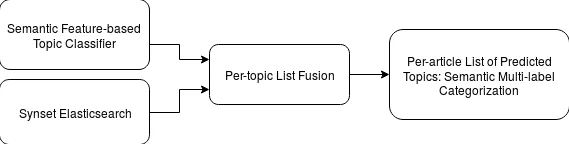
다음으로, 각 토픽(예: 인공지능, 면역학 등)에 대해 ElasticSearch 기반 텍스트 검색을 수행해 토픽 명이 포함된 논문을 긍정 샘플로, 무작위로 선택된 비포함 논문을 부정 샘플로 구성한다. 이렇게 만든 데이터셋으로 One‑vs‑All 로지스틱 회귀 혹은 선형 SVM을 학습시켜 토픽별 확률 점수를 출력한다. 다중 라벨 상황을 고려해 각 논문에 대해 모든 토픽의 확률을 계산하고, 토픽당 상위 100K 논문을 랭킹 리스트(R)로 만든다.
동시에, BabelNet에서 추출한 동의어 집합(synset)을 이용해 토픽 명을 확장하고, 동일한 ElasticSearch 엔진으로 확장된 쿼리를 실행한다. 이 과정에서 얻은 랭킹 리스트(S)는 텍스트 매칭 기반이지만, 동의어를 포함함으로써 의미적 커버리지를 확보한다.
핵심 기여는 두 랭킹을 융합하는 평균‑랭크 기법이다. 논문 A가 S와 R 양쪽에 존재하면 t_A = (s_A + r_A)/2 로 점수를 부여하고, 한쪽에만 존재하면 t_A = r_A × |S| 로 보정한다. 여기서 a 라는 하이퍼파라미터를 도입해 최종 Fusion 리스트의 크기를 |F| = a × |S| 로 제한한다. 이 설계는 높은 정밀도와 재현율을 동시에 달성하도록 조정 가능하게 만든다.
실험은 프랑스 ISTEX 메타데이터(21백만 문서 중 20년 이내 영문 논문)와 Web of Science에서 추출한 33개 토픽을 대상으로 수행되었다. BabelNet을 선택한 이유는 과학·기술 분야 용어에 대한 풍부한 동의어 정보를 제공하기 때문이다. 결과는 기존 Synset‑ElasticSearch 단일 방식 대비 평균 F1이 0.71에서 0.79로 11% 상승했으며, LDA 기반 토픽 모델링 대비 학습·추론 시간이 3배 이상 빠른 것으로 나타났다. 또한, 메타데이터 자동 풍부화 후 검색 실험에서 교차 학문 검색 성공률이 크게 증가했다.
이 논문의 한계는 (1) 토픽 수가 제한적이며(33개), (2) BabelNet 의존도가 높아 최신 용어나 신생 분야에 대한 커버리지가 부족할 수 있다는 점이다. 향후 연구에서는 동적 어휘 확장을 위한 최신 언어 모델(GPT‑4, BERT 기반)과, 사용자 피드백을 반영한 온라인 학습 메커니즘을 도입해 지속 가능한 메타데이터 업데이트 체계를 구축할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기