데이터베이스 기반 자동 변조 분류와 SMO 최적화
초록
본 논문은 스펙트럼 기반 특징을 이용해 SVM을 SMO 방식으로 학습하고, 학습된 특징을 데이터베이스에 저장하여 실시간으로 미지의 신호를 빠르게 분류하는 자동 변조 분류(AMC) 시스템을 제안한다. 15 dB SNR에서 99 % 이상, 5 dB SNR에서도 95 % 이상의 정확도를 달성한다.
상세 분석
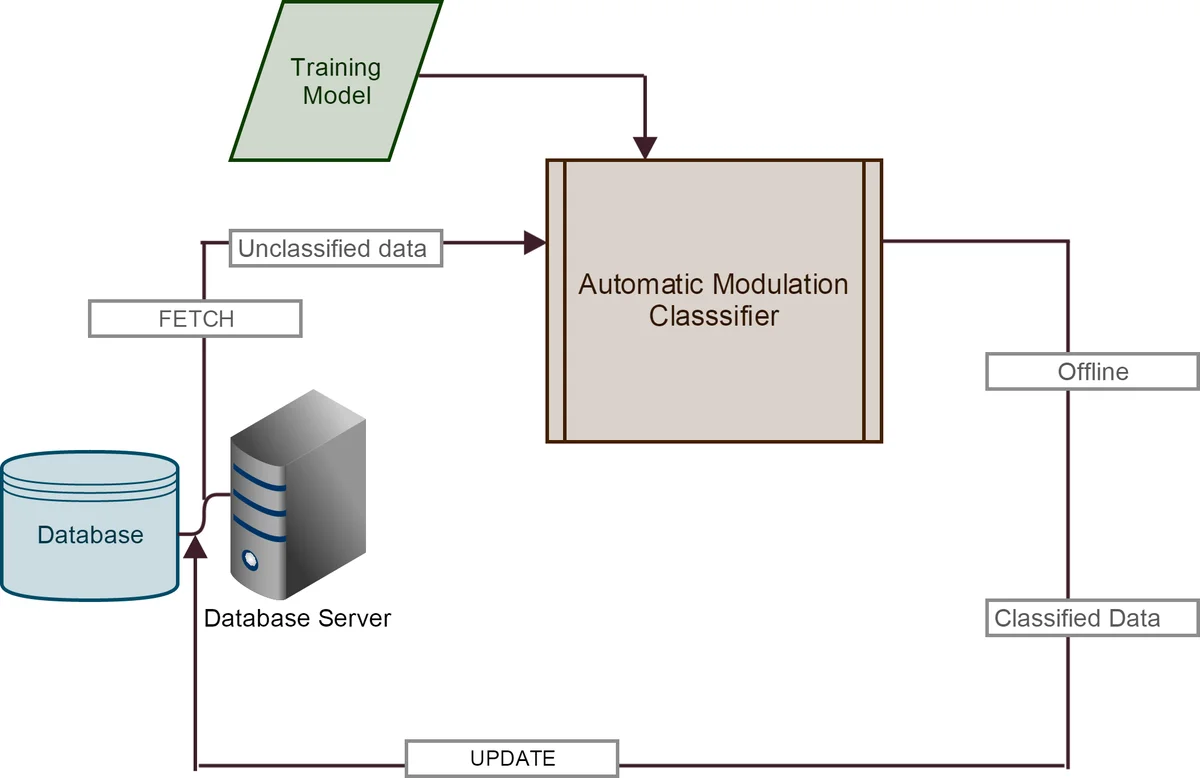
이 연구는 인지 라디오(Cognitive Radio) 환경에서 기본 사용자(Primary User)의 변조 방식을 신속히 파악하기 위해 자동 변조 분류(AMC)를 데이터베이스와 결합한 새로운 프레임워크를 제시한다. 기존 SVM 기반 AMC는 학습 데이터가 많아질수록 훈련 및 분류 시간이 급격히 증가하는 단점이 있었으며, 특히 실시간 스펙트럼 감시에서는 비현실적이었다. 논문은 이러한 문제를 해결하기 위해 두 가지 핵심 기술을 도입한다. 첫째, Sequential Minimal Optimization(SMO) 알고리즘을 사용해 선형 SVM을 효율적으로 학습한다. SMO는 라그랑주 승수를 두 변수씩 최적화함으로써 메모리 요구량을 선형 수준으로 낮추고, 대규모 데이터셋에서도 수천 배 빠른 학습 속도를 제공한다. 둘째, 학습된 특징 벡터를 관계형 데이터베이스(MySQL) 안에 저장하고, 미지의 신호가 들어올 때 실시간으로 특징을 추출해 데이터베이스와 매칭한다. 이 과정에서 WEKA 형식(arff) 파일을 동적으로 생성해 SMO 모델에 입력하고, 매칭 성공 시 바로 변조 종류를 반환한다.
특징 추출 단계는 Nandi와 Azzouz가 제안한 9개의 스펙트럼 기반 통계량(γmax, σdp, σap, P, σaa, σaf, σa, μa⁴², μf⁴²)을 그대로 사용한다. 이러한 특징은 순간 진폭, 위상, 주파수의 평균·분산·왜도·첨도를 이용해 아날로그·디지털 변조를 구분하도록 설계되었으며, 특히 저 SNR 환경에서도 강인한 구분력을 제공한다. MATLAB 시뮬레이션으로 AM, FM, DSB, LSB, USB, 2ASK, 4ASK, 2FSK, 4FSK, 2PSK, 4PSK 등 11개의 변조 클래스를 생성하고, 각 클래스당 다중 SNR(5 dB~25 dB)에서 10,000개 이상의 샘플을 확보했다.
실험 결과, 데이터베이스 기반 접근법은 비데이터베이스(플랫 파일) 방식에 비해 분류 시간 복잡도가 선형에 가깝게 유지되며, 알려진 신호 수가 1000개 수준까지 증가해도 실시간 요구를 충족한다. 정확도 측면에서는 SNR = 15 dB에서 99 % 이상, SNR = 5 dB에서 95 % 이상의 정확도를 기록했으며, 혼동 행렬을 통해 대부분의 변조가 명확히 구분됨을 확인했다.
한계점으로는(1) 동시에 하나의 신호만 전송된다고 가정했으며, (2) 보조 사용자(Secondary User)의 전력은 매우 낮아 간섭을 무시했으며, (3) 데이터베이스에 저장된 변조 종류가 사전에 정의된 11종에 한정돼 새로운 변조가 등장하면 탐지 불가능하다는 점을 들 수 있다. 또한, 지능형 악성 사용자가 기존 변조 특성을 모방할 경우 식별이 어려워 추가적인 행동 기반 탐지 기법이 필요하다.
전반적으로 이 논문은 SMO 기반 SVM과 데이터베이스 매칭을 결합해 AMC의 실시간성 및 정확성을 크게 향상시킨 점에서 의미가 크다. 향후 연구에서는 다중 사용자 동시 전송, 새로운 변조 유형 자동 학습, 그리고 딥러닝 기반 특징 추출과의 하이브리드 모델을 탐색함으로써 인지 라디오 시스템의 보안과 효율성을 더욱 강화할 수 있을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기