아티스트 라벨을 활용한 음악 표현 학습
본 논문은 음악 트랙에 자연스럽게 부여되는 아티스트 라벨을 활용해 딥러닝 기반 오디오 특징을 학습한다. 전체 아티스트 라벨을 이용한 기본 DCNN과, 아티스트 정체성을 기반으로 한 부분 집합을 이용해 쌍(pair) 혹은 삼중(triplet) 관계를 학습하는 Siamese DCNN 두 가지 모델을 제안한다. 학습된 특징을 장르 분류와 음악 검색 등 전이 학습 시나리오에 적용해 기존의 장르·태그 기반 모델과 성능을 비교한다. 결과적으로 Siames…
저자: Jiyoung Park, Jongpil Lee, Jangyeon Park
본 논문은 음악 트랙에 자동으로 부여되는 아티스트 라벨을 활용해 딥러닝 기반의 음악 특징을 학습하는 새로운 접근법을 제시한다. 기존 연구는 비지도 학습(희소 코딩, K‑means, RBM 등)과 의미 라벨(장르, 무드 등)을 이용한 지도 학습에 주로 의존했으며, 각각 데이터 활용 효율성·특징 표현력, 라벨 노이즈·비용 문제를 안고 있었다. 저자는 이러한 한계를 극복하기 위해 “아티스트 라벨”이라는 객관적 메타데이터를 사용한다. 아티스트는 곡마다 고유하게 부여되며, 각 아티스트가 고유한 음악적 스타일을 가지고 있다는 가정 하에, 아티스트 구분 능력이 음악적 특성 구분 능력으로 전이될 수 있음을 제안한다.
**모델 설계**
두 가지 딥 컨볼루션 신경망(DCNN) 모델을 설계하였다.
1. **Basic Model**: 1‑D CNN 구조(5개의 컨볼루션‑맥스풀링 레이어, 배치 정규화·ReLU)로, 입력은 128‑채널 mel‑spectrogram이다. 마지막 은닉층의 256‑차원 벡터를 특징으로 추출하고, 아티스트 수만큼의 소프트맥스 출력과 교차 엔트로피 손실을 사용해 전통적인 다중 클래스 분류 방식으로 학습한다. 이 모델은 구현이 간단하지만, 아티스트 수가 많아지면 출력층 파라미터가 급증하고, 새로운 아티스트가 추가될 때마다 전체 재학습이 필요하다는 단점이 있다.
2. **Siamese Model**: 기본 모델과 동일한 CNN을 공유하지만, 트리플렛(앵커‑양성‑음성) 구조와 네거티브 샘플링을 도입한다. 앵커와 동일 아티스트의 곡을 양성, 다른 아티스트의 곡을 음성으로 설정하고, 코사인 유사도 기반 마진 힌지 손실을 최적화한다. 네거티브 샘플 수를 4, 마진을 0.4로 설정해 실험적으로 최적화하였다. 이 구조는 아티스트 수에 독립적인 파라미터 규모를 유지하면서 대규모 데이터셋에서도 효율적으로 학습할 수 있다.
**데이터 및 학습**
학습 데이터는 Million Song Dataset(MSD)과 7digital 30초 프리뷰를 사용하였다. 아티스트 라벨은 500, 1,000, 2,000, 5,000, 10,000개의 아티스트를 각각 20곡씩 균등하게 선택해 구성했으며, 훈련·검증·테스트를 15:3:2(또는 17:1:2) 비율로 나누었다. 태그 라벨 모델은 Last.fm 태그를 사용해 동일한 규모(90,000곡)로 구성하였다. 전처리는 1024‑point FFT, 512‑point hop, 22050 Hz 샘플링 레이트, 128‑채널 mel‑spectrogram, 로그 압축을 적용했으며, 3초 길이의 컨텍스트 윈도우를 무작위 추출해 입력으로 사용했다. 최적화는 SGD(Nesterov 0.9)와 학습률 감소 전략을 사용했으며, 드롭아웃(0.5)과 제로 패딩을 적용하였다.
**평가**
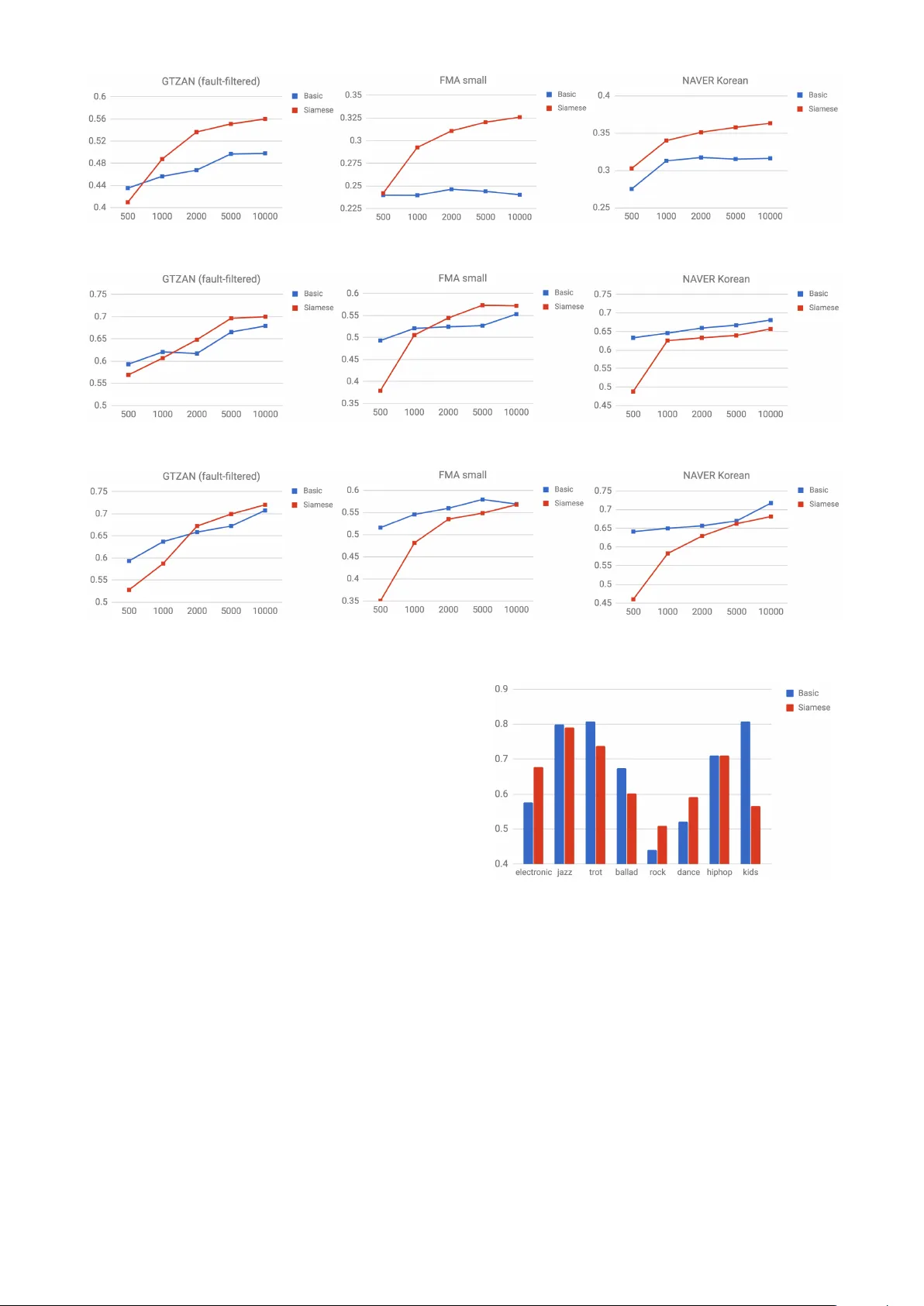
학습된 특징을 세 가지 타깃 데이터셋(GTZAN fault‑filtered, FMA small, NAVER Korean)에서 두 가지 방식으로 평가했다.
1. **특징 유사도 기반 검색**: 코사인 유사도로 곡 간 거리를 측정하고, 평균 정밀도(MAP)로 성능을 측정했다.
2. **전이 학습**: k‑NN(k=20)과 선형 소프트맥스 분류기를 사용해 장르 분류 정확도를 평가했다.
**실험 결과**
- **Siamese Model**은 모든 타깃 데이터셋에서 MAP 점수가 가장 높아 검색 성능이 우수했다. 이는 아티스트 라벨 기반 특징이 장르 간 유사성을 잘 반영한다는 것을 의미한다.
- **Basic Model**은 일부 데이터셋, 특히 NAVER Korean에서 k‑NN 및 선형 소프트맥스 정확도가 Siamese보다 높았다. 이는 기본 모델이 학습 과정에서 명시적인 클래스 구분 정보를 더 많이 보존하기 때문으로 해석된다.
- **Tag‑label Model**은 장르와 직접 연관된 태그를 사용했기 때문에, 선형 소프트맥스 분류에서는 전반적으로 가장 높은 정확도를 기록했다.
**논의**
두 모델의 장단점을 정리하면 다음과 같다.
- **Basic Model**: 구현이 간단하고, 작은 규모에서는 높은 분류 성능을 보인다. 그러나 아티스트 수가 늘어나면 파라미터가 급증하고, 새로운 아티스트가 추가될 때 전체 재학습이 필요하다.
- **Siamese Model**: 대규모 아티스트 집합에서도 파라미터 규모가 일정하고, 네거티브 샘플링을 통해 효율적으로 학습한다. 유사도 기반 검색에 강점이 있지만, 명시적인 클래스 구분 정보가 약해 특정 분류 과제에서는 성능이 떨어질 수 있다.
**결론 및 향후 연구**
아티스트 라벨만으로도 의미 있는 일반 음악 특징을 학습할 수 있음을 입증하였다. 목적에 따라 Basic 혹은 Siamese 구조를 선택하면 된다. 향후 연구에서는 아티스트 라벨과 기존 의미 라벨을 결합한 멀티태스크 학습, 더 정교한 네거티브 샘플링 전략, 그리고 다른 메타데이터(앨범, 발매 연도 등)를 활용한 확장 가능성을 탐색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기