대역폭을 넘어서는 적대적 예제로 강화된 음성 인식
본 논문은 Fast Gradient Sign Method(FGSM)로 생성한 적대적 예제를 훈련 데이터에 동적으로 추가하여 DNN 기반 음성 인식 모델의 잡음 및 채널 변동에 대한 강인성을 향상시키는 방법을 제안한다. Aurora‑4와 CHiME‑4 단일 채널 과제에서 기존 다조건 훈련 대비 평균 14 %·5 % 정도의 WER 감소를 달성했으며, 교사‑학생(T/S) 학습과 결합했을 때 Aurora‑4에서 23 %의 상대적 개선을 기록하였다.
저자: Sining Sun, Ching-Feng Yeh, Mari Ostendorf
본 논문은 음성 인식 시스템의 견고성을 높이기 위해, Fast Gradient Sign Method(FGSM)를 이용해 훈련 중에 동적으로 적대적 예제를 생성하고 이를 데이터 증강에 활용하는 새로운 접근법을 제시한다. 기존의 데이터 증강 기법은 주로 외부 잡음, 리버브, 채널 변형 등을 인위적으로 추가하는 방식으로, 데이터 다양성을 인위적으로 확대한다. 그러나 이러한 방법은 실제 환경에서 발생할 수 있는 복합적인 왜곡을 완전히 반영하지 못한다는 한계가 있다.
이에 저자들은 모델 파라미터에 기반한 적대적 예제를 활용한다. 구체적으로, 현재 모델 파라미터 θ와 입력 x, 정답 라벨 y에 대해 교차 엔트로피 손실 J(θ, x, y)의 입력에 대한 그래디언트를 계산하고, 그 부호만을 취해 작은 상수 ε(논문에서는 )를 곱한 δ_FGSM = ε·sign(∇_x J)를 만든다. 이 perturbation은 각 특성 차원마다 +ε 혹은 –ε 로 제한되어 인간이 인지하기 어려운 미세 변형을 만든다. 이렇게 생성된 적대적 예제 x_adv = x + δ_FGSM는 원본 라벨 y와 동일한 정답을 갖도록 하여, 원본 데이터와 동일한 학습 목표를 유지한다.
훈련 과정은 다음과 같다. 먼저 일반적인 미니배치 B를 사용해 모델을 한 스텝 업데이트한다. 그 후 현재 파라미터를 이용해 B에 대한 δ_FGSM을 계산하고, 이를 통해 적대적 예제 배치 B_adv를 만든다. 마지막으로 B_adv를 사용해 또 한 번 모델을 업데이트한다. 이 과정을 매 미니배치마다 반복함으로써, 모델은 자신의 현재 약점(손실이 급격히 증가하는 입력 영역)을 스스로 탐색하고, 그 약점을 보완하도록 학습된다. 알고리즘 1은 이 흐름을 명확히 제시한다.
실험은 두 개의 대표적인 잡음·채널 변동 평가 코퍼스인 Aurora‑4와 CHiME‑4 단일 채널 트랙을 대상으로 수행되었다. 두 코퍼스 모두 CNN 기반 acoustic model을 사용했으며, Aurora‑4에서는 40‑dim mel‑filterbank와 11‑frame 컨텍스트, CHiME‑4에서는 40‑dim fMLLR과 동일한 컨텍스트를 입력으로 채택했다. CNN 구조는 2개의 convolutional layer(각 256 feature map)와 4개의 fully‑connected layer(1024 units)로 구성되었고, ReLU 활성화와 Adam 옵티마이저를 사용했다.
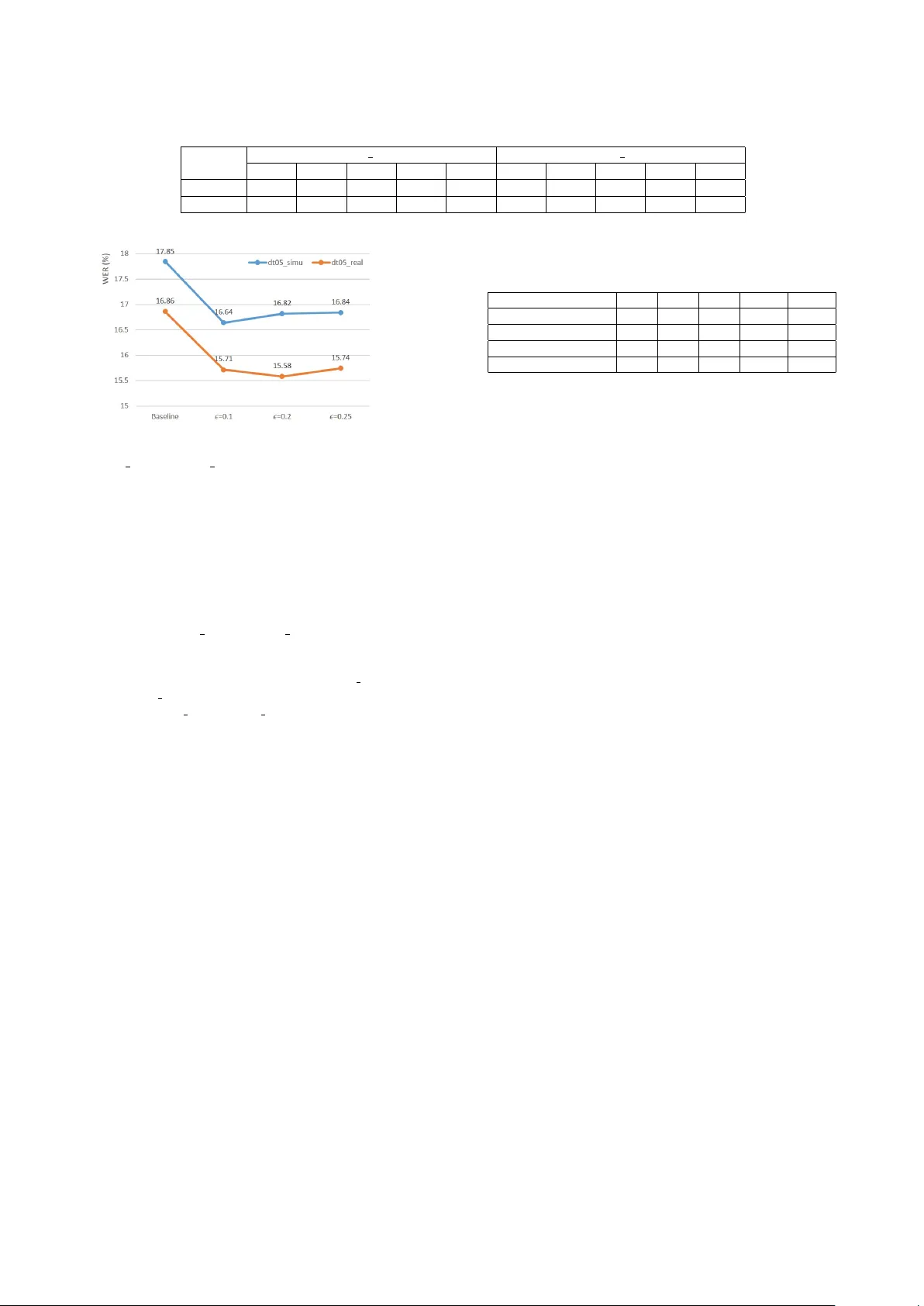
먼저 ε() 값에 대한 탐색을 수행했다. Aurora‑4에서는 dev 0330 셋에서 ε = 0.3이 최적임을 확인했으며, CHiME‑4에서는 ε = 0.1이 가장 좋은 성능을 보였다. 이 최적값을 적용한 결과, Aurora‑4의 4개 테스트 셋(A, B, C, D) 평균 WER이 11.05 %에서 9.49 %로 14.1 % 상대 개선을 달성했다. 특히 가장 어려운 D 셋(노이즈 + 채널 왜곡)에서는 18.6 % 감소를 기록했다. CHiME‑4에서는 시뮬레이션(dt05 simu)과 실제 녹음(dt05 real) 모두에서 약 5 % 수준의 일관된 WER 감소를 얻었으며, 모든 잡음 환경(버스, 카페, 보행자 거리, 거리)에서 개선 효과가 관찰되었다.
또한, 교사‑학생(T/S) 학습과의 결합 효과를 평가했다. Aurora‑4에서는 깨끗한 데이터로 교사 모델을, 잡음이 섞인 데이터로 학생 모델을 훈련시켰으며, 학생 모델 학습 시 원본 손실과 교사 모델 출력에 대한 손실을 가중 평균한 복합 손실 함수를 사용했다. 이때 적대적 예제 증강을 동시에 적용하면, 최종 WER이 23 % 정도 상대적으로 감소하는 최상의 결과를 얻었다. 이는 적대적 데이터 증강과 T/S 학습이 서로 보완적으로 작용한다는 중요한 시사점을 제공한다.
논문의 주요 기여는 다음과 같다. (1) 모델 파라미터에 기반한 적대적 예제를 훈련 중에 실시간으로 생성해 데이터 증강에 활용함으로써, 기존 변환 기반 증강이 포착하지 못하는 미세한 입력 공간의 약점을 보완한다. (2) FGSM을 사용함으로써 계산 비용을 최소화하고, 대규모 음성 데이터셋에도 손쉽게 적용 가능하도록 설계했다. (3) Aurora‑4와 CHiME‑4라는 두 개의 서로 다른 잡음·채널 변동 환경에서 일관된 성능 향상을 입증했으며, 교사‑학생 학습과 결합했을 때 추가적인 이득을 확인했다.
결론적으로, 적대적 예제 기반 데이터 증강은 음성 인식 모델의 일반화와 잡음 강인성을 동시에 향상시키는 효과적인 전략이며, 특히 실시간 혹은 대규모 학습 파이프라인에 쉽게 통합될 수 있다. 향후 연구에서는 보다 정교한 적대적 생성 방법(예: PGD, CW 공격)이나, 멀티‑모달(음성 + 텍스트) 상황에서의 적용 가능성을 탐색할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기