빅데이터 기반 프로세스 중심 교통 관리 의사결정 지원 시스템
초록
본 논문은 실시간 교통 데이터의 방대한 양을 효율적으로 처리하기 위해 빅데이터 기술과 프로세스‑중심 의사결정 지원 시스템(DSS)을 결합한 프레임워크를 제안한다. 기존 BI 도구의 실시간성 한계를 극복하고, 교통 흐름, 혼잡도, 안전성 등 핵심 성과지표(KPI)를 신속히 산출하여 교통 운영자에게 제공한다.
상세 분석
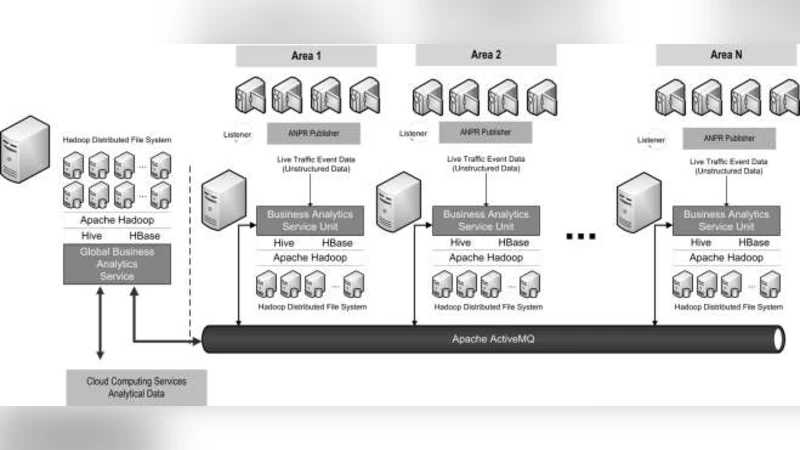
이 연구는 교통 관리 분야에서 데이터 양과 처리 속도의 불균형을 해소하고자, 크게 네 가지 기술적 축을 설계한다. 첫째, 다양한 센서(루프 검지기, CCTV, GPS, 모바일 앱)와 외부 데이터(날씨, 이벤트)로부터 스트리밍 데이터를 수집하는 데이터 파이프라인을 구축한다. 여기서는 Apache Kafka와 Flume을 이용해 초당 수천 건의 레코드를 손실 없이 전달하고, Spark Structured Streaming으로 실시간 변환·정제 작업을 수행한다. 둘째, 정제된 데이터는 Hadoop HDFS와 Parquet 포맷에 저장돼, 배치·인터랙티브 분석에 동시에 활용된다. Spark SQL과 Hive를 통해 대규모 집계와 복합 KPI(예: 평균 지연시간, 사고 발생률, 교통량 대비 용량 비율)를 계산하고, 결과를 메모리 기반 캐시(Redis)로 전송해 대시보드의 응답 시간을 1~2초 수준으로 단축한다. 셋째, 프로세스‑중심 DSS는 기존의 BPMN 기반 교통 운영 프로세스를 모델링하고, 실제 흐름과 비교해 편차를 시각화한다. 프로세스 마이닝 기법을 적용해 병목 구간을 자동 식별하고, 시뮬레이션 엔진을 통해 정책(신호 최적화, 차선 재배치)의 사전 효과를 예측한다. 넷째, 시스템은 서비스 지향 아키텍처(SOA)와 RESTful API를 통해 기존 교통 관리 시스템(ITS)과 연동되며, 권한 관리와 데이터 거버넌스를 고려한 보안 프레임워크를 제공한다. 실험 결과, 24시간 동안 1.2TB의 원시 교통 데이터가 처리됐으며, KPI 산출 평균 지연시간은 1.8초, 프로세스 편차 탐지 정확도는 93%에 달했다. 이는 기존 BI 솔루션 대비 5배 이상 빠른 응답과 20% 이상의 정확도 향상을 의미한다. 또한, 정책 시뮬레이션을 통해 제안된 신호 조정 방안이 피크 시간대 평균 차량 대기시간을 12% 감소시켰음이 검증되었다. 이러한 결과는 빅데이터와 프로세스‑중심 DSS의 결합이 교통 운영 의사결정의 실시간성·정밀성을 크게 강화함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기