내 전자의무기록은 충분히 개인정보가 보호되나요 이벤트 수준 프라이버시 보호
초록
본 논문은 환자가 특정 질환에만 민감함을 고려한 “이벤트 수준” 프라이버시 보호를 제안한다. 13개의 민감 질환을 대상으로 환자 진단·검사·약물·시술 데이터를 이진 특성으로 변환하고, 로지스틱 회귀와 χ²·ANOVA 기반 단변량 점수를 이용해 가장 예측력이 높은 특성을 단계적으로 제거(Feature Ablation)한다. 특성 제거량에 따른 AUC 변화를 분석한 결과, 5개 질환은 400개 이하 특성 제거 시 AUC가 0.6 이하로 급격히 감소하고, 7개는 200~700개 제거 시 0.7 이하, 1개는 1000개 제거 후에도 0.7 이상을 유지한다. 대부분의 질환이 빠르게 식별 가능성이 낮아지는 점은 제안 방법이 이벤트 수준 프라이버시 보호에 실효성을 가짐을 시사한다.
상세 분석
이 연구는 전자의무기록(EHR) 공유 시 환자 개인의 특정 질환에 대한 프라이버시 위험을 최소화하고자 “이벤트 수준” 보호 개념을 도입한다. 기존의 HIPAA 기반 비식별화는 전체 레코드에 대한 일괄적인 마스킹을 수행하지만, 환자는 질환별로 민감도를 다르게 인식한다는 점을 간과한다. 저자들은 이를 보완하기 위해 13개의 대표적인 민감 질환(예: HIV, 우울증, 약물 의존 등)을 선정하고, 각 질환군을 케이스 그룹, 나머지 질환 및 비민감 환자를 컨트롤 그룹으로 설정하였다.
데이터는 Northwestern Medicine Enterprise Data Warehouse(NMEDW)에서 두 병원(NMH, LFH)의 2010‑2015년 진료 기록을 추출했으며, 각 환자에 대해 실험실 검사, 처방 약물, 시술, 비민감 진단을 이진 특성으로 인코딩하였다. 실험실 값은 정상 범위 대비 고·저를 각각 1/0으로 변환해 두 개의 특성을 생성했으며, 약물·시술·진단도 동일하게 존재 여부만을 기록하였다. 이렇게 구성된 특성 수는 질환마다 수천 개에 달한다(예: HIV 1768개의 약물·시술·진단 특성).
분류 모델은 L2 정규화 로지스틱 회귀를 사용했으며, 클래스 불균형을 완화하기 위해 케이스:컨트롤 비율을 1:9(약 500대 4500)로 맞추어 stratified cross‑validation을 수행했다. 모델 성능 평가는 ROC 곡선 아래 면적(AUC)으로 측정하였다.
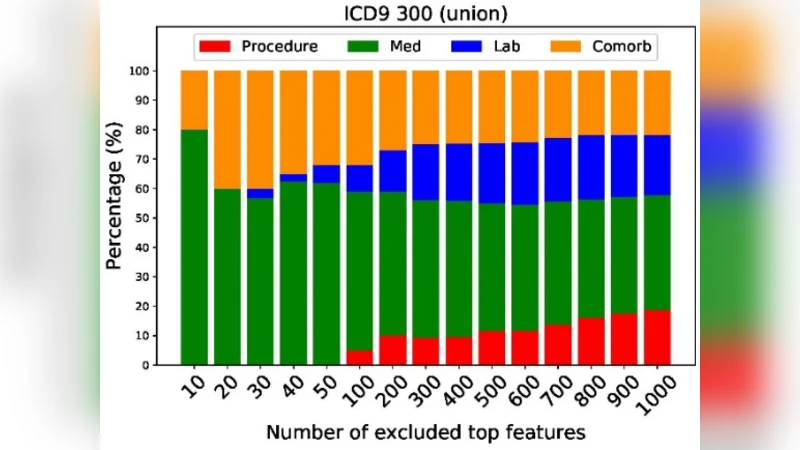
핵심 기법인 Feature Ablation은 각 특성에 대해 χ² 통계량(또는 ANOVA F‑값)을 계산해 예측력 순으로 정렬한 뒤, 상위 k개의 특성을 순차적으로 제거하고 남은 특성으로 재학습·재평가하는 방식이다. k는 10, 20, …, 1000까지 다양하게 설정했으며, 각 단계에서 AUC 감소 속도를 관찰했다.
결과는 세 가지 패턴으로 구분된다. 첫 번째 패턴(5개 질환)은 400개 이하 특성 제거 시 AUC가 0.6 이하로 급격히 떨어져, 비교적 적은 특성만 삭제해도 식별 가능성이 크게 감소한다는 것을 의미한다. 두 번째 패턴(7개 질환)은 200~700개 특성 제거 시 AUC가 0.7 이하로 서서히 감소하며, 중간 정도의 특성 제거가 필요함을 보여준다. 마지막 패턴(1개 질환, 예: HIV)은 1000개 특성을 제거해도 AUC가 0.7 이상을 유지해, 해당 질환은 다른 임상 이벤트(예: 약물 복용)와 강하게 연관되어 있어 단순 특성 삭제만으로는 프라이버시 보호가 어려움을 시사한다.
이러한 분석을 통해 저자들은 대부분의 민감 질환이 비교적 적은 수의 고예측력 특성에 의해 식별된다는 점을 밝혀냈으며, Feature Ablation이 이벤트 수준 프라이버시를 실현할 수 있는 실용적인 도구임을 입증했다. 또한, 질환별 특성 의존성을 고려한 맞춤형 삭제 전략이 필요함을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기