강화학습 기반 무선 공존 관리 시스템을 위한 자원 할당 최적화
초록
산업 현장에서 라이선스‑프리 주파수를 공유하는 다양한 무선 시스템 간의 간섭을 최소화하기 위해, 논문은 중앙 조정점(CCP)을 강화학습 에이전트로 활용한 자원 할당 프레임워크를 제안한다. 딥 Q‑네트워크(DQN)와 이중 딥 Q‑네트워크(DDQN)를 비교 실험한 결과, DDQN이 98 % 이상의 예측 정확도를 달성하며 실시간 채널 할당에 유리함을 확인하였다.
상세 분석
본 연구는 산업용 무선 환경에서 발생하는 복합적인 간섭 문제를 해결하기 위해 ‘중앙 공존 관리’라는 구조적 접근을 채택하였다. 핵심은 CCP(중앙 조정점)를 강화학습 에이전트로 모델링하고, 환경 관측값을 두 가지 형태—FFT 기반 스펙트럼 스냅샷과 무선 간섭 분류(WIC) 결과—로 구성한 점이다. 이러한 관측은 에이전트가 현재 주파수 사용 현황을 정량적으로 파악하고, 향후 자원 점유를 예측하도록 만든다.
행동 공간은 각 무선 네트워크(WN)에 할당되는 채널 집합으로 정의되며, 정적 채널 선택을 사용하는 WLAN과 주파수 호핑을 수행하는 BT와 같은 이질적인 시스템을 동시에 지원한다. 보상은 각 WN이 보고하는 QoC(품질‑공존) 파라미터, 즉 전송 성공률, 패킷 손실률 등을 종합한 값으로 설정되어, 에이전트가 실제 통신 품질에 기반해 학습하도록 설계되었다.
알고리즘적으로는 전통적인 Q‑러닝에 딥 뉴럴 네트워크를 결합한 DQN을 기본 모델로 삼고, 과대평가 문제를 완화하기 위해 두 개의 Q‑함수를 독립적으로 학습하는 DDQN을 도입하였다. 경험 재플레이와 타깃 네트워크를 활용해 학습 안정성을 높였으며, 하이퍼파라미터(학습률 1e‑4, 할인율 0.96 등)는 실험을 통해 최적화하였다.
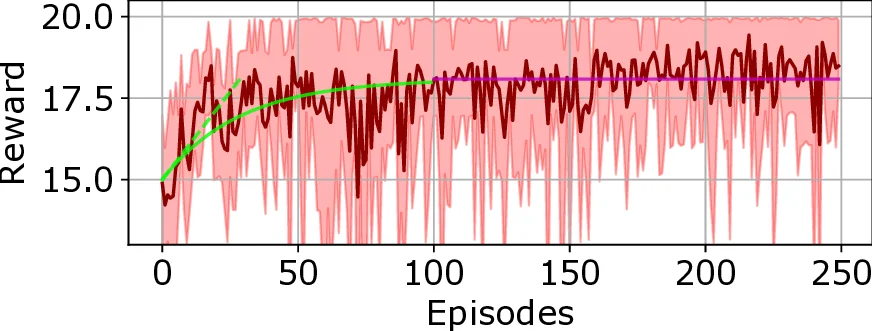
시뮬레이션은 GNU Radio와 OpenAI Gym을 이용해 구현되었으며, 단일 WN이 4개의 정적 채널 중 하나를 선택하도록 설정된 ‘lean’ 환경에서 두 가지 간섭 시나리오(정적 간섭기와 순차 호핑 간섭기)를 테스트하였다. 각 에피소드는 20 스텝으로 구성되고, 250 에피소드를 15번 반복해 평균 보상을 측정했다. 결과는 DDQN이 모든 시나리오에서 평균 보상 19.6 이상을 기록, 이는 20 스텝 중 거의 모든 전송이 성공했음을 의미한다. DQN에 비해 DDQN은 특히 간섭기가 채널을 자주 변환하는 경우에도 높은 예측 정확도를 유지했다.
이러한 결과는 (1) 중앙 집중형 강화학습이 비협조적 간섭기를 포함한 복합 환경에서도 효과적인 자원 예측·할당을 수행할 수 있음을, (2) DDQN이 노이즈와 비선형 간섭 특성을 가진 무선 환경에서 안정적인 정책 학습에 유리함을 입증한다. 또한, 관측에 WIC와 같은 고도화된 분류기를 결합하면 더욱 정교한 정책 설계가 가능하다는 확장 가능성을 시사한다. 향후 연구에서는 다중 WN·다중 WT 상황, 비동기 트래픽, 실시간 제어 채널 구현 등을 포함한 스케일업이 요구된다.
댓글 및 학술 토론
Loading comments...
의견 남기기