NES 음악 데이터베이스: 다중 악기와 표현적 연주 특성을 담은 대규모 코퍼스
NES-MDB는 NES APU의 네 개 모노포닉 악기를 대상으로, 악보와 함께 다이나믹·톤 색상 정보를 제공하는 대규모 데이터셋이다. 블렌드된 악보, 분리된 악보, 그리고 표현적 악보 세 가지 형태로 제공되며, 작곡과 연주 두 단계의 별도 학습을 가능하게 한다. 논문은 기본 RNN, LSTM, DeepBach 등 여러 모델을 실험해 작곡과 표현 매핑의 베이스라인을 제시한다.
저자: Chris Donahue, Huanru Henry Mao, Julian McAuley
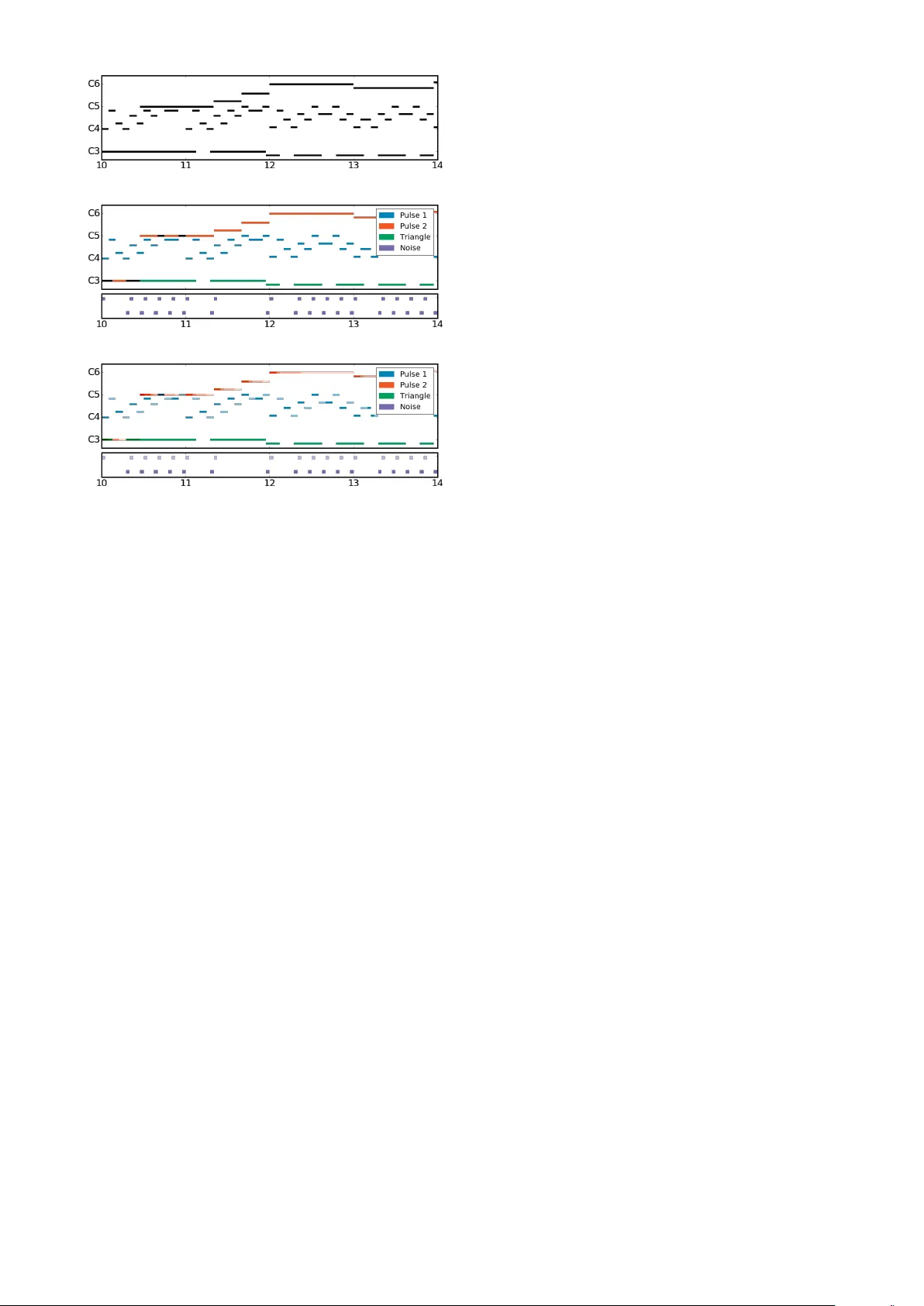
본 논문은 NES(닌텐도 엔터테인먼트 시스템)용 오디오 프로세서(APU)의 특성을 활용한 대규모 음악 데이터셋인 NES-MDB를 소개한다. NES APU는 두 개의 펄스 파형(P1, P2), 하나의 삼각파(TR), 하나의 노이즈 파형(NO)으로 구성된 네 개의 단일 음성 채널만을 지원한다. 이러한 하드웨어 제약은 복잡한 다중 악기 음악을 단순화된 형태로 표현할 수 있게 하며, 각 채널의 음높이, 볼륨(velocity), 그리고 펄스와 노이즈의 경우 톤 색상(timbre)까지 정확히 기록할 수 있다.
데이터는 기존 NES 게임 ROM에 포함된 VGM(Video Game Music) 포맷의 레지스터 쓰기 로그를 에뮬레이션해 44.1 kHz 해상도로 추출한 뒤, 24 Hz로 다운샘플링해 상징적 시퀀스로 변환한다. 이 과정에서 원본 머신 코드가 보존하는 모든 표현적 정보—노트 시작·종료 시점, 다이나믹 변화, 파형 전환—가 그대로 데이터에 포함된다. 결과적으로 NES-MDB는 (1) 블렌드된 스코어(blended score), (2) 분리된 스코어(separated score), (3) 표현적 스코어(expressive score) 세 가지 형태로 제공된다. 블렌드된 스코어는 기존의 폴리포닉 MIDI 데이터와 유사하게 모든 채널을 하나의 이진 행렬로 합친 것이며, 동일한 피치를 여러 채널이 동시에 연주할 경우 정보가 손실된다. 반면 분리된 스코어는 각 채널을 독립적인 시퀀스로 표현해 채널 간 상호작용을 명시적으로 모델링할 수 있다. 표현적 스코어는 분리된 스코어에 velocity와 timbre 정보를 추가해, 실제 NES 하드웨어가 재생하는 정확한 사운드를 재현한다.
논문은 이 데이터셋을 활용한 세 가지 연구 과제를 정의한다. 첫 번째는 블렌드된 스코어를 학습해 작곡의 의미론을 파악하는 ‘blended composition’이다. 두 번째는 각 채널을 독립적인 시퀀스로 다루는 ‘separated composition’으로, Eq. 3에 제시된 바와 같이 시간·채널 간 의존성을 모두 고려한다. 세 번째는 ‘expressive performance’로, 분리된 스코어를 입력으로 받아 각 시점의 velocity와 timbre를 예측하는 조건부 확률 P(e|c)를 학습한다.
실험에서는 다양한 베이스라인과 최신 모델을 비교한다. unigram·bigram 모델은 가장 단순한 확률 분포를 사용해 ‘무음’ 혹은 ‘이전 음’만을 예측한다. RNN Soloist과 LSTM Soloist은 각 채널을 독립적으로 학습하는 모델이며, LSTM Quartet은 하나의 LSTM이 네 채널 전체를 동시에 처리한다. DeepBach은 각 시점을 임베딩하고 양방향 LSTM으로 과거·미래 컨텍스트를 모두 활용해 예측한다. 평가 지표는 Negative Log‑Likelihood(NLL)와 정확도이며, 특히 ‘Points of Interest(POI)’—음이 시작·종료되는 시점—에 대한 성능을 별도로 측정한다. POI는 전체 시점 대비 변동이 적어, 모델이 실제 음악적 변화를 포착했는지를 판단하는 핵심 지표가 된다.
결과는 다음과 같다. 전체 시점에서 LSTM Quartet이 가장 낮은 NLL을 기록했지만, POI 정확도는 DeepBach에 비해 현저히 낮았다. DeepBach은 양방향 처리 덕분에 POI에서 30% 이상 높은 정확도를 보였으며, 이는 미래 정보를 활용할 수 있기 때문이다. 그러나 실시간 생성에는 미래 정보를 사용할 수 없으므로, 실제 음악 생성 파이프라인에서는 LSTM Quartet과 같은 전향 모델이 더 적합하다. 표현적 성능 과제에서는 velocity와 timbre를 동시에 예측하는 모델이 단순 노트 예측 모델보다 NLL이 크게 개선되었으며, 이는 표현적 특성이 독립적인 정보임을 확인한다.
또한, POI를 인위적으로 강조해 학습시키면 음악이 과도하게 파편화되고 비현실적인 변화를 보이는 문제가 발견돼, 데이터의 고정된 시간 해상도를 그대로 활용하는 것이 바람직함을 제안한다. 전체적으로 NES-MDB는 (1) 하드웨어 제약에 의해 자연스럽게 정형화된 다중 악기 구조, (2) 완전한 표현적 정보 제공, (3) 작곡과 연주를 별도 과제로 분리할 수 있는 설계라는 세 가지 강점을 가진다. 이는 기존의 MIDI 기반 데이터셋이 갖지 못한 ‘정확한 사운드 재현 가능성’과 ‘다중 악기 간 상호작용 모델링’을 동시에 제공함으로써, 음악 생성 연구에 새로운 벤치마크와 실험 플랫폼을 제공한다. 향후 연구에서는 보다 정교한 변분 오토인코더, 트랜스포머 기반 모델, 그리고 강화학습을 통한 표현적 매핑 최적화 등이 탐색될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기